КАТЕГОРИИ:
АстрономияБиологияГеографияДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРиторикаСоциологияСпортСтроительствоТехнологияФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Модель сервера БД

Сервер БД - процесс ОС, имеющий свой порт.
Предположим, пользователь щёлкает по кнопке, на рабочей станции (WS) вызывается программа обработки событий. Если при её выполнении встречается SQL-оператор, то он не выполняется на рабочей станции и передаётся на сервер БД и выполняется ядром СУБД. Ядро разбивает SQL-оператор и обращается к требуемым файлам по шине PCI. После выполнения SQL-оператора результаты возвращаются в прикладную программу, выдавшую запрос, та их обрабатывает и отображает их в виде формы на экране.
В отличие от предыдущей модели, здесь прикладные программы могут выполняться и на сервере в виде триггеров и хранимых процедур.
Триггеры – это программы, к которым обращается ядро СУБД до, и/или после обрабатывания записи в таблице.
Условия срабатывания триггера определяет программист. В теле триггера может быть вызвана хранимая процедура.
Хранимые процедуры – это прикладные программы, являющиеся расширением ядра. В теле хранимой процедуры можно кодировать обращение к СУБД и к хранимым процедурам. К хранимым процедурам можно обращаться и с рабочих станций, и с помощью RPC (Remote Procedure Control).
Основные СУБД данного типа:
1. Oracle
2. MS SQL Server
3. SyBase
4. Informix
5. InterBase
6. Centura
Преимущества модели сервера базы данных:
- Система, разработанная на основе этой модели, имеет большую производительность, чем в случае модели файлового сервера (по шине передаются только SQL-операторы и результаты выполнения SQL-операторов, все промежуточные данные передаются по PCI);
- Эти СУБД поддерживают распределённую обработку (используется оптимизация SQL-запросов, т.е. выделяются подзапросы, которые могут автоматически выполняться на разных серверах);
- В рамках этих СУБД поставляются большое число сервисных продуктов, облегчающих работу с СУБД;
- Ядро СУБД общее для всех рабочих станций.
Недостатки модели сервера базы данных::
- Эти СУБД намного дороже СУБД предыдущего класса;
- В силу большого объёма документации СУБД сложнее в освоении, поэтому необходимо наличие квалифицированных администраторов;
- Так как ядро общее, необходим мощный сервер;
- Для того чтобы проявились преимущества оптимизации SQL-запросов, необходимо наличие в сети нескольких серверов баз данных.
-------------------------------------------------------------------------------------------------------------------------
БИЛЕТ 8
1. Алгоритм вычисления замыкания множества атрибутов в теории проектирования реляционных баз данных.
Замыкание множества атрибутов.
Пусть R- универсальная схема отношений. Замыканием множества атрибутов Х, принадлежащего R (XÍR), называется множество атрибутов Ai1…. Aik, таких, что справедливо следующее выражение:
(XàAi1…. XàAik) ÍF+.
Замыкание множества атрибутов обозначается через Х+.
Правило
Чтобы проверить, принадлежит ли функциональная зависимость XàY замыканию F+ (XàY ÍF+), сначала строят Х+ и если Y Í Х+, то значит XàY Í F+.
Основная задача заключается в построении алгоритма замыкания множества атрибутов.
Алгоритм построения замыкания множества атрибутов.
Это итерационная процедура, включающая следующие шаги:
- i:=0, X0+=X – замыкание множества атрибутов на i-ом шаге.
- Положить X+i+1:= X+iÈV, где V – множеств атрибутов такое, что в F имеется функциональная зависимость Y→Z, для которых YÍ X+i , а VÍZ.
- X+i+1= X+i – это есть X+:= X+i , иначе i:=i+1 и перейти к шагу 2.
Пример замыкания множества атрибутов.
R=(A,B,C,D,E,G),
F=(AB→C, C→A, BC→D. ACD→B, D→EG, BE→C, CG→BD, CE→AG)
X=BD, X+ - ?
- X0+≔BD
- и 3. Оформим в виде таблицы:
| i | Y→Z, для которых YÍ X+i | VÍZ | X+i+1≔ X+iÈV |
| D→EG | EG | EGBD X+1 | |
| BE→C | C | EGBDC X+2 | |
| C→A, BC→D, CG→BD, CE→AG | A | EGBDCA X+3 | |
| AB→C, ACD→B | EGBDCA X+4 |
Т.о. (BD)+ = EGBDCA *Þ
(BD→E, BD→G, BD→B, BD→C, BD→D, BD→A) Ì F+ **
* и ** эквивалентны.
2. Методы выбора записей из исходных таблиц при построении оптимального физического плана выполнения запроса к базе данных.
.
Шаги построения физического плана
При построении оптимального физического плана выполнения SQL-запроса (дерева физических операций) выполняются следующие действия:
1. Последовательно строится множество физических планов на основе логического плана (см. разделы 1.2, 1.3). Физические планы в основном отличаются следующим:
а) методом выбора записей из исходных таблиц (методом реализации подзапросов 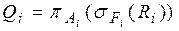 );
);
б) порядком соединения таблиц;
в) методом соединения таблиц (т.е. методом реализации операции естественного соединения  ).
).
2. Для каждого физического плана рассчитывается стоимость его выполнения. Выбирается физический план с наименьшей стоимостью.
Отличие физического плана от логического
Логический план не указывает на то, как должны быть реализованы операции реляционной алгебры (проекция, селекция, декартово произведение, естественное соединение). Физический план определяет, как эти операции будут реализовываться.
Например, логический план может быть реализован с помощью физического плана, представленного на рис. 1.6.

Рис. 1.6. Логический и физический планы выполнения запроса.
Физический план выполняется в следующей последовательности.
1. Здесь операции  реализуются следующим образом: читается вся таблица R1 (TableScan(R1)) и затем каждая запись проверяется, удовлетворяет ли она логическому условию F1, и если да, то из нее выделяются атрибуты, входящие в множество A1 (
реализуются следующим образом: читается вся таблица R1 (TableScan(R1)) и затем каждая запись проверяется, удовлетворяет ли она логическому условию F1, и если да, то из нее выделяются атрибуты, входящие в множество A1 (  ). Получившаяся промежуточная таблица является правым аргументом соединения.
). Получившаяся промежуточная таблица является правым аргументом соединения.
2. Операции  реализуются следующим образом: с помощью индекса читаются записи таблицы R2, удовлетворяющие подусловию φ (IndexScan(R2, φ)). Здесь φ – некоторое подусловие условия F2 по атрибуту, который имеет индекс.
реализуются следующим образом: с помощью индекса читаются записи таблицы R2, удовлетворяющие подусловию φ (IndexScan(R2, φ)). Здесь φ – некоторое подусловие условия F2 по атрибуту, который имеет индекс.
Примеры подусловий φ: a = 5, a > 5, a ≥ 5, a < 5, a ≤ 5 (a – индексированный атрибут таблицы R2).
Считанные записи фильтруются (  ). Получившаяся промежуточная таблица является левым аргументом соединения.
). Получившаяся промежуточная таблица является левым аргументом соединения.
3. Выполняется естественное соединение промежуточных таблиц, полученных на первом и втором шагах, методом сортировки и слияния (SMJ); тут же из получившегося результата выделяется множество атрибутов A.
Оптимизатор для каждого физического плана рассчитывает стоимость. Эта стоимость равна сумме составляющих. Для данного примера имеем:

Каждая из этих составляющих, в свою очередь, включает процессорную составляющую и составляющую дискового ввода-вывода:
C = CCPU + CI/O .
После перебора нескольких физических планов оптимизатор выбирает план с минимальной стоимостью.
Дата добавления: 2015-04-21; просмотров: 125; Мы поможем в написании вашей работы!; Нарушение авторских прав |