КАТЕГОРИИ:
АстрономияБиологияГеографияДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРиторикаСоциологияСпортСтроительствоТехнологияФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Алгоритм Робертса 1 страница
Это математически элегантный алгоритм.
Вначале удаляются из каждого тела те ребра или грани, которые экранируются самим телом. Затем каждое из видимых ребер каждого тела сравнивается с каждым из оставшихся тел для определения того, какая его часть или части экранируются этими телами.
Трудоемкость —  .
.
Это в сочетании с распространением растровых дисплеев привело к снижению интереса к этому алгоритму. Но математические методы, используемые в нем, просты, мощны и точны. В последующем введение предварительной сортировки по z снижает трудоемкость.
Необходимо, чтобы все изображаемые тела были выпуклыми. Невыпуклые тела разбиваются на выпуклые части. Выпуклое тело с плоскими гранями представляются набором пересекающихся плоскостей. Уравнение плоскости в пространстве:
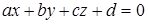 .
.
В матричной форме:  , или
, или
 — представляет собой плоскость.
— представляет собой плоскость.
Поэтому любое выпуклое тело можно выразить матрицей тела, состоящей из коэффициентов уравнений плоскостей:
 .
.
Каждый столбец содержит коэффициенты одной плоскости. Любая точка пространства в однородных координатах:
 .
.
Если точка S лежит на плоскости, то
 .
.
Если точка S не лежит на плоскости, то знак этого скалярного произведения показывает по какую сторону от плоскости расположена точка. Если точка внутри тела — знак «+», если вне — «–».
Если точка S не лежит на плоскости, то знак этого скалярного произведения показывает по какую сторону от плоскости расположена точка (точка внутри тела — знак «+», точка вне тела — знак «–»).
- Иерархический Z-буфер.
Всевозрастающая сложность геометрических сцен в компьютерной графике дает прекрасную почву для исследования и разработки различных алгоритмов, по определению видимости объектов. Представим себе виртуальную прогулку по максимально детализированному геометрическому набору объектов, представляющему собой целый город с его растительностью, зданиями, мебелью внутри зданий со всеми ее ящиками, ножками, ручками и т.д. Традиционные алгоритмы определения текущей видимости объектов, реализуемые на существующем аппаратном обеспечении, вряд ли справятся с задачей визуализации сцен подобной сложности на скоростях, соответствующих интерактивной графике. И пройдет еще немало времени, прежде чем будет создано то «железо», которое будет способно в одиночку справиться с данной задачей. Поэтому, чтобы выжать максимум из имеющегося в нашем распоряжении аппаратного обеспечения, мы нуждаемся в создании быстрых алгоритмов, способных значительно ускорить просчет видимых частей и отброс всей невидимой части сцены.
Существует, по крайней мере, три типа когерентных связей, присущих процессам просчета видимости объектов, умелое применение которых позволит резко увеличить скорость работы алгоритмов просчета видимой и отсечения невидимой геометрии.
1 Когерентность в объектном пространстве: во многих случаях однократное вычисление позволит определить видимость целого набора рядом расположенных объектов.
2. Когерентность в отображаемом двумерном пространстве: очень часто однократное вычисление позволяет определить видимость объекта, покрывающего определенный набор пикселей на экране.
3. Переходная когерентность — информация о видимости объектов в одном кадре, зачастую может быть использована для ускорения просчетов в следующем кадре.
Далее мы представляем алгоритм просчета видимости объектов, реализующий все три типа когерентных связей и позволяющий на несколько порядков опередить традиционные технологии.
Доминирующими технологиями для просчета видимости являются Z—buffer scan conversion и ray tracing. Т.к. алгоритмы, использующие Z—буфер, не очень эффективно работают с частично прозрачными поверхностями, поэтому мы ограничим обсуждение моделями, состоящими из непрозрачных поверхностей. В случае применения таких моделей для определения видимости нам достаточно луча, направленного из камеры до поверхности, таким образом, мы остановимся только на алгоритмах Z—буферизации и ray casting (тот же ray tracing, только без учета вторичного луча.
Традиционный Z—буферинг достаточно эффективно использует когерентные связи в отображаемом пространстве по ходу scan conversion. При реализации алгоритма обычно сначала делаются базовые вычисления для каждого полигона, а затем производится и обновление данных по каждому пикселю полигона. Но вот проблема традиционного Z—buffer состоит в том, что этот подход совершенно не использует когерентные связи в объектном пространстве и переходную когерентность между кадрами. Каждый полигон просчитывается отдельно, и нам недоступна информация об уже произведенных расчетах в предыдущем кадре. Для сцен с высокой и сверхвысокой геометрической сложностью, как, например, модель города, данный подход очень неэффективен. Традиционный алгоритм будет, например, тратить время на просчет каждого полигона у каждого объекта, каждого ящика у каждого письменного стола в здании, даже если все здание не будет видно, и все потому, что видимость определяется только на пиксельном уровне.
Традиционные методы трассировки луча (ray tracing и ray casting), наоборот, используют когерентные связи в объектном пространстве, реализуя некоторого рода пространственное деление. Луч из глаз наблюдателя (или камеры) проходит через структуру поделенного пространства, пока не коснется первой видимой поверхности. Как только луч достиг поверхности, уже нет необходимости рассматривать остальные поверхности в подпространствах, расположенных за первой поверхностью по ходу луча. Таким образом, мы исключаем из дальнейшей обработки значительное количество геометрии. В этом контексте мы получили значительное преимущество по сравнению с традиционным Z—буфером, но не использовали когерентность в отображаемом пространстве и переходные взаимосвязи между кадрами. Здесь нужно заметить, что в алгоритмах основанных на трассировке лучей все же вполне возможно утилизовать переходные когерентные связи, но реализовать когерентность в отображаемом пространстве (image space coherence) представляется очень и очень сложной задачей.
В нашем случае мы представляем алгоритм, который объединяет в себе силы сразу двух (ray casting и Z—buffering) алгоритмов. Для утилизации когерентных связей в объектном пространстве мы будем использовать рекурсивное деление пространства на 8 подпространств. Реализацию когерентности в пространстве изображения возложим на Z—buffer scan conversion, усовершенствованный при помощи Z—пирамиды, которая позволит нам очень эффективно отсекать невидимые части геометрии сцены. И наконец, для использования переходной когерентности, в качестве стартовой точки начала всего алгоритма для каждого кадра мы будем использовать уже просчитанную видимую геометрию из предыдущего кадра. Представляемый алгоритм не сложен для реализации и применим для полигонных наборов любой сложности. И чем сложнее использованная геометрия в сцене и чем выше разрешения конечного изображения, тем заметнее будет разница в скорости просчетов по сравнению с традиционными алгоритмами.
Уже были неоднократные попытки ускорить работу традиционных алгоритмов. Каждая из этих попыток представляла собой работу по использованию некоторых аспектов когерентности, присущих самой идее просчета видимости. Но ни одна из этих попыток не давала возможность совместного использования всех трех видов когерентности.
Основная масса наработок в области ray tracing расширяла возможности использования только объектной когерентности. Переходная когерентность очень редко использовалась на практике, но для ряда случаев все же есть несколько методик. Если все объекты являются выпуклыми и остаются неподвижными во время движения самой камеры, то существуют некоторые закономерности в процессе изменения видимости самих объектов. Алгоритм трассирования в состоянии отследить и использовать эти закономерности. С другой стороны, если камера является неподвижной, то тогда лучи, которые не попадают под влияние движущихся объектов, могут быть легко определены, и их можно взять из процесса обработки предыдущего кадра. Но мы по-прежнему не видим ни одного метода, способного извлечь выгоду из когерентности изображения, ввиду того, что каждый пиксель просчитывается независимо от состояния соседних. Существуют, однако, алгоритмы эвристического предсказания результатов ray tracing на конкретный пиксель по текущему состоянию соседних, однако мы и здесь не получаем гарантированного решения по использованию когерентности изображения при ray tracing.
При реализации алгоритмов Z—buffer (и алгоритмов scan conversion вообще) возникает совершенно противоположная проблема. Обычная растеризация с применением Z—буфера в подавляющем большинстве случаев связана с необходимостью предварительного просчета каждого полигона, и только после этого можно непосредственно перейти к самой растеризации посредством scan conversion, при которой последовательно обновляются все задействованные пиксели. Эта схема, сама по себе, прекрасно утилизирует когерентность изображения, поэтому необходимо задуматься только над объектной и переходной когерентностью.
Для того, чтобы быть максимально понятыми, для начала введем несколько соглашений.
1) Относительно Z—буфера, полигон будет считаться невидимым, если ни один пиксель полигона не будет лежать ближе значения Z, уже записанного в соответствующую позицию Z—буфера.
2) Куб в пространстве будет считаться невидимым, если три его грани, обращенные к наблюдателю, будут невидимыми полигонами.
3) Все дочерние ветви дерева (octree), полученного при делении пространства, будут считаться невидимыми, если мы определим, что кубическое подпространство, ассоциируемое с данными ветвями, будет считаться невидимым. С учетом этих определений, мы можем сформулировать следующее условие, позволяющее нам комбинировать 2D Z—буфер с делением пространства на кубические субпространстве: если куб считается невидимым на основе значений в Z—буфере, то все полигоны, которые полностью находятся в данном кубическом субпространстве, тоже будут невидимыми. Что нам это дает? А то, что если мы методом scan conversion просчитаем грани определенного субпространства из состава octree и определим, что все пиксели этого куба находятся позади соответствующих значений в Z—буфере, то можем смело игнорировать всю геометрию находящуюся внутри данного куба.
Исходя из вышесказанного, базовый алгоритм легко сконструировать. Для начала вся геометрическое пространство последовательно размещается в структуре дерева (octree), ассоциируя каждый примитив с наименьшим кубическим пространством дерева, в котором примитив помещается полностью.
Дерево рекурсивного деления пространства на восемь подпространств формируется следующим образом. Вся сцена помещается в минимально возможный, выровненный по осям координат, куб. Этот куб будет являться базовым (root) и соответствовать началу (корню) дерева. Дальнейшая процедура является рекурсивной по сути и начинается с проверки содержащихся в данном кубе примитивов, и если их количество меньше определенного порогового значения, то процедура ассоциирует данный примитив с этим кубом и заканчивает рекурсию. Если нет, то с кубом ассоциируется любой примитив, который пересекает хотя бы одну из трех плоскостей, виртуально делящих куб на восемь равных подпространств, и производится деление куба этими тремя плоскостями. В результате этого мы получим восемь новых дочерних кубиков с размером сторон 1/2 от размеров родительского куба. Эти восемь кубиков будут представлять первую ветвь дерева. Полученные кубы снова проверяются на соответствие содержащихся в них примитивов определенному пороговому количеству, и, если необходимо, каждый не удовлетворивший условию куб будет снова поделен на восемь меньших кубиков (подпространств), означающих собой появление новых, дочерних ветвей у родительской ветви и т.д. Этот процесс будет продолжаться до тех пор, пока каждый из кубов не будет содержать примитивов меньше, чем пороговое значение, или пока рекурсия не достигнет своего самого глубокого уровня.
Закончив с формированием дерева, мы рекурсивно выполняем следующую процедуру: начиная с базового (root) куба, мы проверяем, попадает ли данный куб в поле зрения (viewing frustum), если НЕТ — на этом и закончим, если же ДА, то методом scan conversion для граней определяем видимость данного куба. Если куб не видим — заканчиваем, если видим — то рендеризуем геометрию, ассоциированную с данным кубом, а затем переходим к его дочерним ветвям (меньшим по размерам кубам) и последовательно выполняем вышеприведенную процедуру, но уже для этих ветвей.
Базовый алгоритм имеет несколько характеристик, на которые надо обратить особое внимание. Первое: он рендеризует ту геометрию, которая содержится только в видимых кубах (видимых ветвях дерева). При этом часть просчитанных примитивов может быть полностью невидимой, но все они считаются "видимыми частично". Частично видимыми мы их будем называть исходя из следующих соображений: всегда найдется такая точка в пространстве, в которой данный полигон станет полностью видимым, и эта точка будет находиться не дальше, чем длина диагонали куба, содержащего данный полигон. Это значительное преимущество по отношению к обычному усечению геометрии под поле зрения камеры (culling to the viewing frustum). В дополнение к этому, наш алгоритм не тратит время на ненужные ветви дерева разбиений, так как он посещает только те ветви, родительские структуры которых — видимы. Что еще более важно, наш алгоритм никогда не посещает одни и те же ветви дважды. А этот недостаток присущ алгоритмам ray tracing, где корень дерева посещается каждый раз для каждого нового пикселя, а другие ветви могут повторно посещены десятки тысяч раз. Как результат, наш базовый алгоритм осуществляет culling гораздо более эффективно.
Однако у этого алгоритма есть и слабые места. Например, алгоритм ассоциирует некоторые небольшие примитивы с большим кубом в том случае, если примитив пересекает плоскости, делящие куб на дочерние кубы. Маленький треугольник, который пересекает центр корневого (базового) куба, например, будет рендеризоваться каждый раз, пока модель является видимой. Для исключения подобного поведения есть два варианта: первый — подрезать (clip) проблематичный полигон так, чтобы он полностью уместился в значительно более меньших дочерних подпространствах (кубах). Но это неизбежно приведет к увеличению количества полигонов в структуре данных. Второй вариант — ассоциировать этот полигон сразу с несколькими ветвями. Этот вариант мы и выберем. Для его реализации нам необходимо несколько модифицировать базовый алгоритм построения дерева (octree). Если мы обнаружим, что некоторый примитив пересекается с плоскостями деления куба, но значительно меньше размеров самого куба, мы не станем ассоциировать его с этим кубом. Вместо этого мы ассоциируем его сразу с несколькими дочерними кубами, которые он пересекает. В результате, так как он ассоциирован с нескольким подпространствами сразу, при рендеризации мы встретим его несколько раз. Поэтому, как только мы встретим его первый раз, пометим его как "отрендеренный" в структуре данных и таким образом мы исключим его повторную растеризацию в текущем кадре.
Дерево делений объектного пространства (object space octree) позволяет нам отсечь значительную долю невидимой геометрии со скоростью, присущей scan conversion для граней кубических подпространств, из состава octree. Так как кубические пространства могут занимать значительную площадь в пересчете на пиксели, то такой вариант применения scan conversion может оказаться очень "дорогим" удовольствием.
Чтобы понизить стоимость процедуры определения видимости кубических пространств, мы будем использовать Z—пирамиду. В большинстве случаев для больших полигонов, Z—pyramid позволяет очень быстро определить, видим он или нет, исключая при этом попиксельные операции.
По сути, Z—пирамида очень напоминает собой пирамиду текстур с mip-levels.
Смысл Z—пирамиды — это использование базового (стандартного) Z—буфера в качестве основания пирамиды. Это основание будет являться самым точным уровнем во всей пирамиде. Следующий, более грубый, уровень будет представлять собой набор значений, полученный путем выбора самого большого (наиболее удаленного) значения из четырех близлежащих значений предыдущего, более точного, уровня. И так далее. Таким образом, каждая, запись в пирамиде будет представлять собой максимальное значение глубины из определенной квадратной области базового Z—буфера и соответствовать определенному фрагменту экрана (тайлу). Самый верхний, наиболее грубый, уровень пирамиды (ее вершина) будет представлять единственную запись, содержащую самое большое значение координаты Z из базового Z—буфера и соответствовать максимальной глубине всего изображения.
Поддерживать пирамиду в актуальном состоянии просто: каждый раз, когда мы обновляем значение базового Z—буфера, мы последовательно продвигаем это значение по более грубым уровням и остановимся в тот момент, когда встретим ту запись, значение которой находится так же далеко, как новое значение Z.
Проверка на видимость при помощи Z—пирамиды осуществляется следующим образом. Мы находим ту запись в пирамиде, которая отображает минимально возможную квадратную площадь экрана полностью содержащей исследуемый полигон. И если Z значение ближайшей вершины полигона будет дальше значения, содержащегося в этой записи, мы немедленно определим, что полигон невидим. Этим методом мы будем пользоваться для определения видимости как ветвей octree, так и для определения видимости полигонов самой модели.
Несмотря на то, что пирамида позволяет нам достаточно быстро определить видимость полигонов и отсечь невидимые, этот базовый алгоритм страдает от тех же недостатков, что и в случае с octree. Исходя из структуры пирамиды, где каждая запись соответствует определенной площади на экране (называемой квадрантом, или тайлом), маленький полигон, расположенный в центре экрана, будет сравниваться с самым грубым уровнем, находящимся в вершине пирамиды. Несмотря на то, что результат будет все равно аккуратным и в этом случае, мы теряем в производительности, так как на определение видимости такого незначительного полигона понадобится самый максимальный рекурсивный цикл.
Окончательный алгоритм определения видимости реализуется путем рекурсивного применения базового алгоритма через всю пирамиду, начиная с вершины. Если базовый алгоритм не может определить, что полигон является невидимым, мы переходим к следующему, более точному уровню пирамиды. Здесь мы попытаемся определить, что полигон является невидимым во всех четырех тайлах, которые он пересекает. Для каждого из этих квадрантов мы сравним ближайшее значение Z—полигона со значением, находящимся в Z—пирамиде. Если значение из пирамиды находится ближе, мы знаем, что полигон невидим в данном квадранте.
Если мы не можем определить, что полигон невидим хотя бы в одном из квадрантов, мы переходим на следующий, еще более точный уровень пирамиды для этого квадранта и пытаемся снова. В конце концов, мы сможем сказать, что полигон или полностью невидим, или мы дойдем до самого точного уровня пирамиды и найдем единичный видимый пиксель. Т.е. мы или отбросим полигон, или "нарисуем" один из пикселей этого полигона. Когда мы таким образом найдем все видимые пиксели, мы скажем, что произвели hierarchical scan conversion.
Потенциальная проблема с окончательным алгоритмом определения заключается в том, что может быть очень "дорого" вычислять ближайшее значение Z полигона для конкретного квадранта.
Альтернативой может быть сравнение значения Z из пирамиды с ближайшим Z целого полигона на всех стадиях рекурсии. В этом случае алгоритм гораздо шустрее, и его легче реализовать, но теперь он не является окончательным. Потому что итогом такого подхода становится либо утверждение, что полигон невидим, либо мы дойдем до уровня пикселя и не сможем сказать, видим он или нет. При возникновении такой ситуации с неопределенностью алгоритм должен переключиться на проверку данного пикселя стандартным вариантом scan conversion. На испытаниях в нашей лаборатории мы реализовали именно такой подход.
- Алг. трассировки лучей.
При рассмотрении этого алгоритма предполагается, что наблюдатель находится на положительной полуоси Z, а экран дисплея перпендикулярен оси Z и располагается между объектом и наблюдателем.
Удаление невидимых (скрытых) поверхностей в алгоритме трассировки лучей выполняется следующим образом:
— сцена преобразуется в пространство изображения,
— из точки наблюдения в каждый пиксел экрана проводится луч и определяется какие именно объекты сцены пересекаются с лучом,
— вычисляются и упорядочиваются по Z координаты точек пересечения объектов с лучом. В простейшем случае для непрозрачных поверхностей без отражений и преломлений видимой точкой будет точка с максимальным значением Z-координаты. Для более сложных случаев требуется сортировка точек пересечения вдоль луча.
Ясно, что наиболее важная часть алгоритма — процедура определения пересечения, которая в принципе выполняется Rx´Ry´N раз (здесь Rx, Ry — разрешение дисплея по Х и Y, соответственно, а N — количество многоугольников в сцене).
Очевидно, что повышение эффективности может достигаться сокращением времени вычисления пересечений и избавлением от ненужных вычислений. Последнее обеспечивается использованием геометрически простой оболочки, объемлющей объект — если луч не пересекает оболочку, то не нужно вычислять пересечения с ним многоугольников, составляющих исследуемый объект.
При использовании прямоугольной оболочки определяется преобразование, совмещающее луч с осью Z. Оболочка подвергается этому преобразованию, а затем попарно сравниваются знаки Хmin с Хmax и Уmin с Уmax. Если они различны, то есть пересечение луча с оболочкой (см. рис. 12.12)
При использовании сферической оболочки для определения пересечения луча со сферой достаточно сосчитать расстояние от луча до центра сферы. Если оно больше радиуса, то пересечения нет. Параметрическое уравнение луча, проходящего через две точки Р1(х1,у1,z1) и Р2(х2,у2,z2), имеет вид:
Р(t) = Р1 + (Р2 — Р1) ´t
Минимальное расстояние от точки центра сферы Р0(х0,у0,z0) до луча равно:
d2=(х—х0)2+(у—у0)2+(z—z0)2

Рис. 12.12. Определение пересечения луча и оболочки
Этому соответствует значение t:

Если d2>R2, то луч не пересекает объекты, заключенные в оболочку.
Дальнейшее сокращение расчетов пересечений основывается на использовании групп пространственно связанных объектов. Каждая такая группа окружается общей оболочкой. Получается иерархическая последовательность оболочек, вложенная в общую оболочку для всей сцены. Если луч не пересекает какую-либо оболочку, то из рассмотрения исключаются вес оболочки, вложенные в нее и, следовательно, объекты. Если же луч пересекает некоторую оболочку, то рекурсивно анализируются все оболочки вложенные в нее.
Наряду с вложенными оболочками для сокращения расчетов пересечений используется отложенное вычисление пересечений с объектами. Если обнаруживается, что объект пересекается лучом, то он заносится в специальный список пересеченных. После завершения обработки всех объектов сцепы объекты, попавшие в список пересеченных упорядочиваются по глубине. Заведомо невидимые отбрасываются а для оставшихся выполняется расчет пересечений и отображается точка пересечения наиболее близкая к наблюдателю.
Дополнительное сокращение объема вычислений может достигаться отбрасыванием нелицевых граней, учетов связности строк растрового разложения и т.д.
Для сокращения времени вычислений собственно пересечений предложено достаточно много алгоритмов, упрощающих вычисления для определенной формы задания поверхностей.
- Общие сведения о свете. Классификация поверхностей по виду отражения.
Свет – электромагнитная энергия, которая после взаимодействия с окружающей средой попадает в глаз, где в результате химических и физических реакций вырабатываются электроимпульсы, воспринимаемые мозгом.
Через опыт наш мозг учится определять и распознавать множество образов и отпечатков, которые создает свет об окружающей нас действительности. Младенец берет предмет, глядит на него мгновение, затем тащит в рот. Его язык - это прекрасный датчик, и может определять форму и вид поверхности предмета практически так же, как и глаз, а иногда и лучше. Ребенок учится ассоциировать то, что он видит с той формой, которую ему описал язык. Со временем ребенок узнает, что один и тот же предмет может выглядеть по-разному в зависимости от того, как его держать, хотя он по-прежнему является тем же самым предметом. Это очевидно - подумаете вы, но было обнаружено, что слепым с рождения людям, которым медицина вернула зрение, понять вышеизложенное очень сложно. Им также сложно усвоить смысл тени и отражения, суть которых зрячие люди познали еще от рождения. И сам факт того, что вы можете видеть, еще не означает, что вы можете понять то, что видите.
В этом и заключается разница между Данными (Data) и Информацией (Information). Данные - это световой образ, формирующийся на сетчатке глаза. Информация — это интерпретация этого образа нашим мозгом.
Создавая изображение любого вида, вы пытаетесь сформировать световой образ на сетчатке глаза таким образом, чтобы он интерпретировался мозгом как предмет, который отображает это изображение. Тренированный мозг может извлечь огромное количество информации из изображения. Благодаря этому в голове мы можем получить полное трехмерное преставление сцены, изображенной на двухмерной картинке. Чтобы получить это, наш мозг анализирует порядок взаимодействия света со сценой (набором объектов изображенных на картинке) и на основе такого анализа данных выдает нам конечное трехмерное представление сцены.
Разнообразие моделей освещения, применяемых в процессе формирования изображений компьютером, - это попытка увеличить количество информации, которую мозг сможет извлечь. Когда вы, как программист, будете писать фрагменты кода, отвечающего за графику, вам не следует думать: "Я пишу процедуру затенения по Фонгу", вместо этого вам следует рассуждать так: "Я использую визуальный трюк для корректной интерпретации мозгом".
Человеческий мозг может извлечь и интерпретировать 4 информационных ресурса из потока видимых данных.
1) Форма.
Это внешний вид объекта (предмета) в сцене, его видимые границы и края. Глаз человека обладает способностью улучшать четкость воспринимаемого изображения, что позволяет увереннее распознавать края предметов; (к месту сказать, что многие компьютерные программы для обработки изображений используют алгоритмы, позволяющие получать улучшения четкости, подобные тем, какие производит глаз человека.)
2) Оттенки
Блики и тени. Тон и структура поверхностей.
3) Цвет
Три цвета могут быть обнаружены человеческим глазом — красный, зеленый и синий.
4) Движение.
Мозг человека особенно восприимчив к движению объектов. Прекрасно "камуфлированное" животное мгновенно будет обнаружено, если оно пошевелится. Очень часто, если вы потеряли курсор на экране монитора, лучший способ найти его - двинуть мышкой.
Специальные отделы головного мозга отвечают за обработку этих четырех информационных ресурса. Это было неоднократно доказано в случаях анализа черепно-мозговых травм, получаемых человеком. Как только человек получает травму и лишается отдела головного мозга, отвечающего за любой из вышеперечисленных ресурсов, то он сразу утрачивает способность к восприятию этой информации. Например, в одном случае женщина потеряла способность ощущать движение. Она могла видеть так же, как все, за исключением способности чутко определять движение объектов. Например, она могла видеть автомобили на дороге, но никогда не могла сказать с первого взгляда - движутся они или нет.
Способность к восприятию принимается человеком как само собой разумеющееся. Принято считать, если вы можете видеть, то, значит, вы в состоянии определить форму, оттенки, цвет и движение. Но это не всегда так.
Не менее важной является информация, которую мозг добавляет или удаляет во время анализа. Когда мы созерцаем, мы имеем дело с гигантскими объемами информации. Было бы просто невозможным проанализировать и запомнить все сведения до мельчайших деталей. Да это и не нужно. Большая часть сведений (данных), поступающих нам через зрение, не обладают какой-либо ценностью. Мозг автоматически производит фильтрацию этого "мусора", позволяя нам сконцентрироваться на более значимой информации. Что еще более важно, мозг также добавляет недостающую информацию. Человеческое зрение имеет "мертвые зоны", но, тем не менее, мы этого не замечаем, потому что пробелы будут всегда заполнены подходящей информацией. Наш мозг много прощает.
Дата добавления: 2015-04-18; просмотров: 92; Мы поможем в написании вашей работы!; Нарушение авторских прав |