КАТЕГОРИИ:
АстрономияБиологияГеографияДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРиторикаСоциологияСпортСтроительствоТехнологияФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Виды моделей БД
Ядром любой базы данных является модель данных. Модель данных- совокупность структур данных и операций их обработки.
СУБД основывается на использовании иерархической, сетевой или реляционной модели, на комбинации этих моделей или не некотором их подмножестве.
Иерархическая модель данных.
К основным понятиям иерархической структуры относятся: уровень, элемент, связь. Узел это совокупность атрибутов данных, описывающих некоторый объект. На схеме иерархического дерева узлы представляются вершинами графа. Каждый узел на более низком уровне связан только с одним узлом, находящимся на более высоком уровне. Иерархическое дерево имеет только одну вершину (корень дерева), не подчиненную никакой другой вершине и находящуюся на самом верхнем (первом) уровне (см. рис. 5).
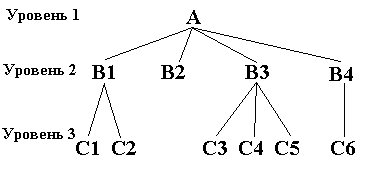
Рис. 5. Иерархическая модель данных
К каждой записи базы данных существует только один (иерархический) путь от корневой записи. Например, для записи С4 путь проходит через записи А и В3.
Пример иерархической структуры. Каждый студент учится в определенной (только одной) группе, которая относится к определенному (только одному) факультету (см. рис. 6).

Рис. 6. Пример иерархической организации данных
Сетевая модель данных
В сетевой структуре каждый элемент может быть связан с любым другим элементом (см. рис 7).
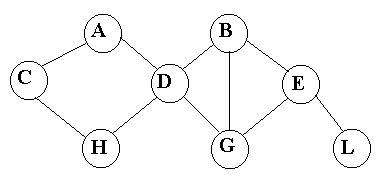
Рис. 7. Сетевая модель данных
Пример сетевой структуры. База данных, содержащая сведения о студентах, участвующих в научно-исследовательских работах (НИРС). Возможно участие одного студента в нескольких НИРС, а также участие нескольких студентов в разработке одной НИРС (см. рис. 8).
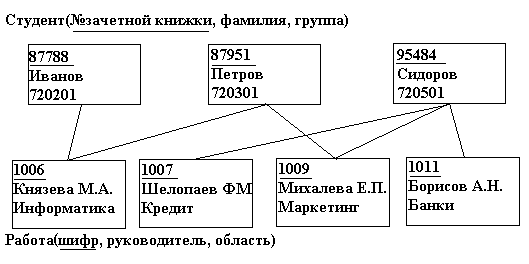
Рис. 8. Пример сетевой организации данных
Реляционная модель данных
Эти модели характеризуются простотой структуры данных, удобным для пользователя представлением и возможностью использования формального аппарата алгебры отношений.
Реляционная модель ориентирована на организацию данных в виде двумерных таблиц. Каждая реляционная таблица (отношение) представляет собой двумерный массив и обладает следующими свойствами:
· каждый элемент таблицы - один элемент данных;
· все столбцы в таблице однородные, т.е. все элементы в столбце имеют одинаковый тип (числовой, символьный и т.д.) и длину;
· каждый столбец имеет уникальное имя;
· одинаковые строки в таблице отсутствуют;
· порядок следования строк и столбцов может быть произвольным.
Пример. Реляционной таблицей можно представить информацию о студентах, обучающихся в вузе.
| №зачетной книжки | Фамилия | Имя | Отчество | Дата рождения | Группа |
| Сергеев | Петр | Михайлович | 01,01,80 | ||
| Петрова | Анна | Владимировна | 15,03,81 | ||
| Анохин | Андрей | Борисович | 14,04,80 |
Поле, каждое значение которого однозначно определяет соответствующую запись, называется простым ключом (ключевым полем). Если записи однозначно определяются значениями нескольких полей, то такая таблица базы данных имеет составной ключ.
Чтобы связать две реляционные таблицы, необходимо ключ первой таблицы ввести в состав ключа второй таблицы (возможно совпадение ключей); в противном случае нужно ввести в структуру первой таблицы внешний ключ - ключ второй таблицы.
Одни и те же данные могут группироваться в таблицы различными способами. Группировка атрибутов в таблицах должна быть рациональной, т.е. минимизирующей дублирование данных и упрощающей процедуры их обработки.
Нормализация отношений -формальный аппарат ограничений на формирование отношений (таблиц), который позволяет устранить дублирование, обеспечивает непротиворечивость хранимых в базе данных, уменьшает трудозатраты на ведение (ввод, корректировку) базы данных.
Выделяют пять нормальных форм отношений. Эти формы предназначены для уменьшения избыточности информации от первой до пятой нормальных форм. Поэтому каждая последующая нормальная форма должна удовлетворять требованиям предыдущей формы и некоторым дополнительным условиям. При практическом проектировании баз данных четвертая и пятая формы, как правило, не используются.
Процедуру нормализации рассмотрим на примере проектирования многотабличной БД Продажи, содержащей следующую информацию:
· Сведения о покупателях.
· Дату заказа и количество заказанного товара.
· Дату выполнения заказа и количество проданного товара.
· Характеристику проданного товара (наименование, стоимость, марка).
Таблица 2. Структура таблицы Продажи
| № | Наименование поля |
| Название Клиента | |
| Обращаться К | |
| Должность | |
| Адрес | |
| Телефон | |
| Дата заказа | |
| Код сотрудника | |
| ФИО Сотрудника | |
| Название товара | |
| Единица Измерения | |
| Цена | |
| Количество |
Таблицу Продажи можно рассматривать как однотабличную БД. Основная проблема заключается в том, что в ней содержится значительное количество повторяющейся информации. Такая структура данных является причиной следующих проблем, возникающих при работе с БД:
· Приходится тратить значительное время на ввод повторяющихся данных. Например, для всех заказов, сделанных одним покупателем, придется каждый раз вводить одни и те же данные о покупателе.
· При изменении адреса или телефона покупателя необходимо корректировать все записи, содержащие сведения о заказах этого покупателя.
· Наличие повторяющейся информации приведет к неоправданному увеличению размера БД. В результате снизится скорость выполнения запросов. Кроме того, повторяющиеся данные нерационально используют дисковое пространство компьютера.
· Любые нештатные ситуации потребуют значительного времени для получения требуемой информации.
Дата добавления: 2015-01-29; просмотров: 450; Мы поможем в написании вашей работы!; Нарушение авторских прав |