КАТЕГОРИИ:
АстрономияБиологияГеографияДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРиторикаСоциологияСпортСтроительствоТехнологияФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Обзор методов Data Mining
Работы студентов (просмотр)
автор: TheKatherin
Стремительное развитие информационных технологий, в частности, прогресс в методах сбора, хранения и обработки данных позволил многим организациям собирать огромные массивы данных, которые необходимо анализировать. Объемы этих данных настолько велики, что возможностей экспертов уже не хватает.
На сегодняшний день интенсивно развивается направление, связанное с интеллектуализацией методов обработки и анализа данных. Интеллектуальные системы анализа данных (ИСАД) призваны минимизировать усилия лица, принимающего решения (ЛПР), в процессе анализа данных, а также в настройке алгоритмов анализа. Многие ИСАД позволяют не только решать классические задачи принятия решения, но и способны выявлять причинно-следственные связи, скрытые закономерности в системе, подвергаемой анализу.
Оглавление
Интеллектуальный анализ данных
Модели представления знаний Data Mining
Анализ подходов и методов решения задачи
1. Обзор существующих методов
2. Свойства методов Data Mining
3. Классификация методов
3.1. Работа с данными
3.2. Подход к обучению математических моделей
3.3 Методы Data Mining также можно классифицировать по задачам Data Mining
Интеллектуальный анализ данных
Data Mining – это сочетание широкого математического инструментария (от классического статистического анализа до новых кибернетических методов) и последних достижений в сфере информационных технологий. В технологии Data Mining гармонично объединились строго формализованные методы и методы неформального анализа, т.е. количественный и качественный анализ данных.
Data Mining (добыча данных, интеллектуальный анализ данных, глубинный анализ данных) — собирательное название, используемое для обозначения совокупности методов обнаружения в данных ранее неизвестных, нетривиальных, практически полезных и доступных интерпретации знаний, необходимых для принятия решений в различных сферах человеческой деятельности. Термин введён Григорием Пятецким-Шапиро в 1989 году.
Основу методов Data Mining составляют всевозможные методы классификации, моделирования и прогнозирования. К методам Data Mining нередко относят статистические методы (дескриптивный анализ, корреляционный и регрессионный анализ, факторный анализ, дисперсионный анализ, компонентный анализ, дискриминантный анализ, анализ временных рядов). Такие методы, однако, предполагают некоторые априорные представления об анализируемых данных, что несколько расходится с целями Data Mining (обнаружение ранее неизвестных нетривиальных и практически полезных знаний).
Одно из важнейших назначений методов Data Mining состоит в наглядном представлении результатов вычислений, что позволяет использовать инструментарий Data Mining людьми, не имеющих специальной математической подготовки. В то же время, применение статистических методов анализа данных требует хорошего владения теорией вероятностей и математической статистикой.
Знания, добываемые методами Data mining, принято представлять в виде моделей.
Модели представления знаний Data Mining

Методы построения таких моделей принято относить к области искусственного интеллекта.
Анализ подходов и методов решения задачи.
1. Обзор существующих методов
К методам и алгоритмам Data Mining относятся:
1. искусственные нейронные сети
2. деревья решений, символьные правила
3. методы ближайшего соседа и k-ближайшего соседа
4. метод опорных векторов
5. байесовские сети
6. линейная регрессия
7. корреляционно-регрессионный анализ
8. иерархические методы кластерного анализа
9. неиерархические методы кластерного анализа, в том числе алгоритмы k-средних и k-медианы
10. методы поиска ассоциативных правил, в том числе алгоритм Apriori
11. метод ограниченного перебора
12. эволюционное программирование и генетические алгоритмы
13. разнообразные методы визуализации данных и множество других методов.
Большинство аналитических методов, используемые в технологии Data Mining – это известные математические алгоритмы и методы. Новым в их применении является возможность их использования при решении тех или иных конкретных проблем, обусловленная появившимися возможностями технических и программных средств. Следует отметить, что большинство методов Data Mining были разработаны в рамках теории искусственного интеллекта.
Метод представляет собой норму или правило, определенный путь, способ, прием решений задачи теоретического, практического, познавательного, управленческого характера.
2. Свойства методов Data Mining
Различные методы Data Mining характеризуются определенными свойствами, которые могут быть определяющими при выборе метода анализа данных. Методы можно сравнивать между собой, оценивая характеристики их свойств.
Основные свойства и характеристики методов Data Mining: точность, масштабируемость, интерпретируемость, проверяемость, трудоемкость, гибкость, быстрота и популярность.
Масштабируемость – свойство вычислительной системы, которое обеспечивает предсказуемый рост системных характеристик, например, быстроты реакции, общей производительности и пр., при добавлении к ней вычислительных ресурсов.
В таблице 1 приведена сравнительная характеристика некоторых распространенных методов. Оценка каждой из характеристик проведена следующими категориями, в порядке возрастания: чрезвычайно низкая, очень низкая, низкая/нейтральная, нейтральная/низкая, нейтральная, нейтральная/высокая, высокая, очень высокая.
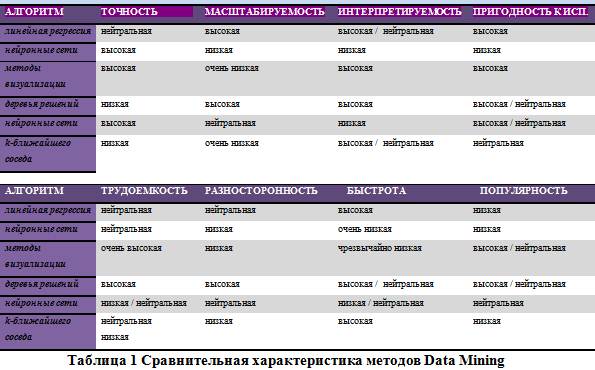
Как видно из рассмотренной таблицы, каждый из методов имеет свои сильные и слабые стороны. Но ни один метод, какой бы не была его оценка с точки зрения присущих ему характеристик, не может обеспечить решение всего спектра задач Data Mining.
3. Классификация методов
3.1. Работа с данными
Все методы Data Mining можно разделить на две большие группы по принципу работы с исходными обучающими данными. В этой классификации верхний уровень определяется на основании того, сохраняются ли данные после Data Mining либо они дистиллируются для последующего использования.
Непосредственное использование данных, или сохранение данных.
В этом случае исходные данные хранятся в явном детализированном виде и непосредственно используются на стадиях прогностического моделирования и/или анализа исключений. Проблема этой группы методов – при их использовании могут возникнуть сложности анализа сверхбольших баз данных.

Выявление и использование формализованных закономерностей, или дистилляция шаблонов.
При технологии дистилляции шаблонов один образец (шаблон) информации извлекается из исходных данных и преобразуется в некие формальные конструкции, вид которых зависит от используемого метода Data Mining. Этот процесс выполняется на стадии свободного поиска, у первой же группы методов данная стадия в принципе отсутствует. На стадиях прогностического моделирования и анализа исключений используются результаты стадии свободного поиска, они значительно компактнее самих баз данных. Конструкции этих моделей могут быть трактуемыми аналитиком либо не трактуемыми (“черными ящиками”).

• Логические методы, или методы логической индукции, включают: нечеткие запросы и анализы; символьные правила; деревья решений; генетические алгоритмы.
Методы этой группы являются, пожалуй, наиболее интерпретируемыми – они оформляют найденные закономерности, в большинстве случаев, в достаточно прозрачном виде с точки зрения пользователя. Полученные правила могут включать непрерывные и дискретные переменные. Следует заметить, что деревья решений могут быть легко преобразованы в наборы символьных правил путем генерации одного правила по пути от корня дерева до его терминальной вершины. Деревья решений и правила фактически являются разными способами решения одной задачи и отличаются лишь по своим возможностям. Кроме того, реализация правил осуществляется более медленными алгоритмами, чем индукция деревьев решений.
• Методы кросс-табуляции: агенты, байесовские (доверительные) сети, кросс-табличная визуализация.
Последний метод не совсем отвечает одному из свойств Data Mining – самостоятельному поиску закономерностей аналитической системой. Однако предоставление информации в виде кросс-таблиц обеспечивает реализацию основной задачи Data Mining – поиск шаблонов, поэтому этот метод можно также считать одним из методов Data Mining.
• Методы на основе уравнений.
Методы этой группы выражают выявленные закономерности в виде математических выражений – уравнений. Следовательно, они могут работать лишь с численными переменными, и переменные других типов должны быть закодированы соответствующим образом. Это несколько ограничивает применение методов данной группы, тем не менее, они широко используются при решении различных задач, особенно задач прогнозирования. Данная классификация разделяет все многообразие методов Data Mining на две группы: статистические и кибернетические методы.
3.2. Подход к обучению математических моделей
Следует отметить, что существует два подхода отнесения статистических методов к Data Mining. Первый из них противопоставляет статистические методы и Data Mining, его сторонники считают классические статистические методы отдельным направлением анализа данных. Согласно второму подходу, статистические методы анализа являются частью математического инструментария Data Mining. Большинство авторитетных источников придерживается второго подхода.
В этой классификации различают две группы методов:
1. статистические методы, основанные на использовании усредненного накопленного опыта, который отражен в ретроспективных данных
2. кибернетические методы, включающие множество разнородных математических подходов
Недостаток такой классификации: и статистические, и кибернетические алгоритмы тем или иным образом опираются на сопоставление статистического опыта с результатами мониторинга текущей ситуации. Преимуществом такой классификации является ее удобство для интерпретации – она используется при описании математических средств современного подхода к извлечению знаний из массивов исходных наблюдений (оперативных и ретроспективных), т.е. в задачах Data Mining.
Статистические методы Data Mining
В эти методы представляют собой четыре взаимосвязанных раздела:
• предварительный анализ природы статистических данных (проверка гипотез стационарности, нормальности, независимости, однородности, оценка вида функции распределения, ее параметров и т.п.);
• выявление связей и закономерностей (линейный и нелинейный регрессионный анализ, корреляционный анализ и др.);
• многомерный статистический анализ (линейный и нелинейный дискриминантный анализ, кластерный анализ, компонентный анализ, факторный анализ и др.);
• динамические модели и прогноз на основе временных рядов.
Арсенал статистических методов Data Mining классифицирован на четыре группы методов:

Кибернетические методы Data Mining
Второе направление Data Mining – это множество подходов, объединенных идеей компьютерной математики и использования теории искусственного интеллекта.

3.3 Классификация по задачам
Методы Data Mining также можно классифицировать по задачам Data Mining. В соответствии с такой классификацией выделяем две группы. Первая из них – это подразделение методов Data Mining на решающие задачи сегментации (т.е. задачи классификации и кластеризации) и задачи прогнозирования. В соответствии со второй классификацией по задачам методы Data Mining могут быть направлены на получение описательных и прогнозирующих результатов.
Описательные методы
Описательные методы служат для нахождения шаблонов или образцов, описывающих данные, которые поддаются интерпретации с точки зрения аналитика.

Прогнозирующие методы
Прогнозирующие методы используют значения одних переменных для предсказания/прогнозирования неизвестных (пропущенных) или будущих значений других (целевых) переменных.


У данного сообщения нет этикеток
Дата добавления: 2015-04-18; просмотров: 454; Мы поможем в написании вашей работы!; Нарушение авторских прав |