КАТЕГОРИИ:
АстрономияБиологияГеографияДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРиторикаСоциологияСпортСтроительствоТехнологияФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Выполнение оценки проекта на основе LOC- и FP-метрик.
Размерно-ориентированные метрики
Размерно-ориентированные метрики прямо измеряют программный продукт и процесс его разработки. Они основываются на LOC-оценках (Lines of code). LOC-оценка – это количество строк в программном продукте.
Исходные данные для расчета этих метрик сводятся в таблицу. На основе таблицы вычисляются размерно-ориентированные метрики производительности и качества (для каждого проекта):
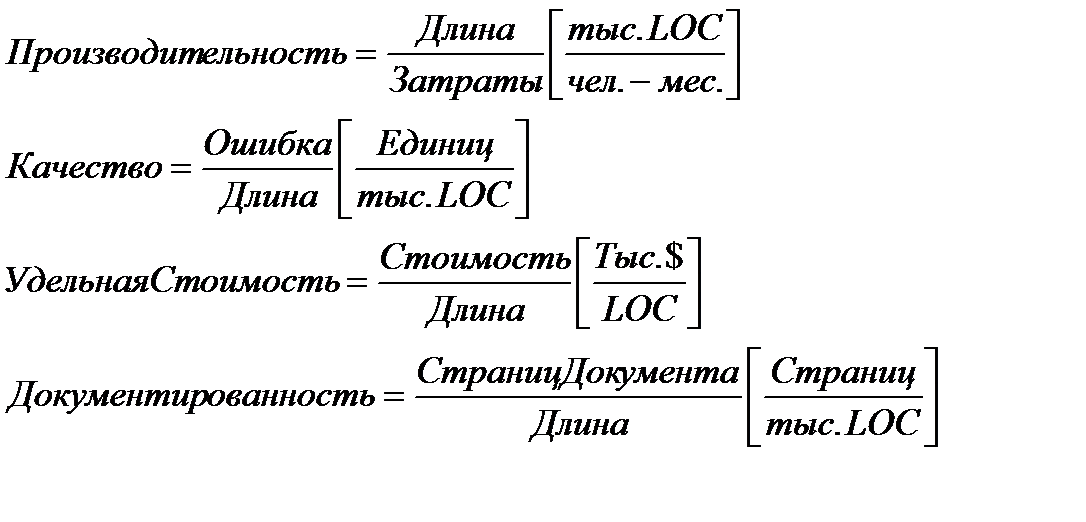
Достоинства размерно-ориентированных метрик:
1) широко распространены;
2) просты и легко вычисляются.
Недостатки размерно-ориентированных метрик:
1) зависимы от языка программирования;
2) требуют исходных данных, которые трудно получить на начальной стадии проекта;
3) не приспособлены к непроцедурным языкам программирования.
Функционально-ориентированные метрики
Функционально-ориентированные метрики косвенно измеряют программный продукт и процесс его разработки. Вместо подсчета LOC-оценки при этом рассматривается не размер, а функциональность или полезность продукта.
Используется 5 информационных характеристик.
1. Количество внешних вводов. Подсчитываются все вводы пользователя, по которым поступают разные прикладные данные. Вводы должны быть отделены от запросов, которые подсчитываются отдельно.
2. Количество внешних выводов. Подсчитываются все выводы, по которым к пользователю поступают результаты, вычисленные программным приложением. В этом контексте выводы означают отчеты, экраны, распечатки, сообщения об ошибках. Индивидуальные единицы данных внутри отчета отдельно не подсчитываются.
3. Количество внешних запросов. Под запросом понимается диалоговый ввод, который приводит к немедленному программному ответу в форме диалогового вывода. При этом диалоговый ввод в приложении не сохраняется, а диалоговый вывод не требует выполнения вычислений. Подсчитываются все запросы — каждый учитывается отдельно.
4. Количество внутренних логических файлов. Подсчитываются все логические файлы (то есть логические группы данных, которые могут быть частью базы данных или отдельным файлом).
5. Количество внешних интерфейсных файлов. Подсчитываются все логические файлы из других приложений, на которые ссылается данное приложение.
Вводы, выводы и запросы относят к категории транзакция. Транзакция — это элементарный процесс, различаемый пользователем и перемещающий данные между внешней средой и программным приложением. В своей работе транзакции используют внутренние и внешние файлы. Приняты следующие определения.
Внешний ввод — элементарный процесс, перемещающий данные из внешней среды в приложение. Данные могут поступать с экрана ввода или из другого приложения. Данные могут использоваться для обновления внутренних логических файлов. Данные могут содержать как управляющую, так и деловую информацию. Управляющие данные не должны модифицировать внутренний логический файл.
Внешний вывод — элементарный процесс, перемещающий данные, вычисленные в приложении, во внешнюю среду. Кроме того, в этом процессе могут обновляться внутренние логические файлы. Данные создают отчеты или выходные файлы, посылаемые другим приложениям. Отчеты и файлы создаются на основе внутренних логических файлов и внешних интерфейсных файлов. Дополнительно этот процесс может использовать вводимые данные, их образуют критерии поиска и параметры, не поддерживаемые внутренними логическими файлами. Вводимые данные поступают извне, но носят временный характер и не сохраняются во внутреннем логическом файле.
Внешний запрос — элементарный процесс, работающий как с вводимыми, так и с выводимыми данными. Его результат — данные, возвращаемые из внутренних логических файлов и внешних интерфейсных файлов. Входная часть процесса не модифицирует внутренние логические файлы, а выходная часть не несет данных, вычисляемых приложением (в этом и состоит отличие запроса от вывода).
Внутренний логический файл — распознаваемая пользователем группа логически связанных данных, которая размещена внутри приложения и обслуживается через внешние вводы.
Внешний интерфейсный файл — распознаваемая пользователем группа логически связанных данных, которая размещена внутри другого приложения и поддерживается им. Внешний файл данного приложения является внутренним логическим файлом в другом приложении.
Каждой из выявленных характеристик ставится в соответствие сложность. Для этого характеристике назначается низкий, средний или высокий ранг, а затем формируется числовая оценка ранга.
Для транзакций ранжирование основано на количестве ссылок на файлы и количестве типов элементов данных. Для файлов ранжирование основано на количестве типов элементов-записей и типов элементов данных, входящих в файл.
Тип элемента-записи — подгруппа элементов данных, распознаваемая пользователем в пределах файла.
Тип элемента данных — уникальное нерекурсивное (неповторяемое) поле, распознаваемое пользователем.
После сбора всей необходимой информации приступают к расчету метрики — количества функциональных указателей FP (Function Points). Автором этой метрики является А. Албрехт (1979).
Исходные данные для расчета сводятся в таблицу.

В таблицу заносится количественное значение характеристики каждого вида (по всем уровням сложности). Места подстановки значений отмечены прямоугольниками (прямоугольник играет роль метки-заполнителя). Количественные значения характеристик умножаются на числовые оценки сложности. Полученные в каждой строке значения суммируются, давая полное значение для данной характеристики. Эти полные значения затем суммируются по вертикали, формируя общее количество. Количество функциональных указателей вычисляется по формуле
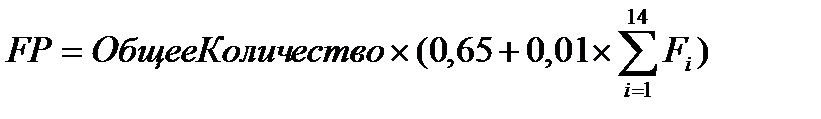
где Fi — коэффициенты регулировки сложности.
Каждый коэффициент может принимать следующие значения: 0 — нет влияния, 1 — случайное, 2 — небольшое, 3 — среднее, 4 — важное, 5 — основное.
После вычисления FP на его основе формируются метрики производительности, качества и т. д.:
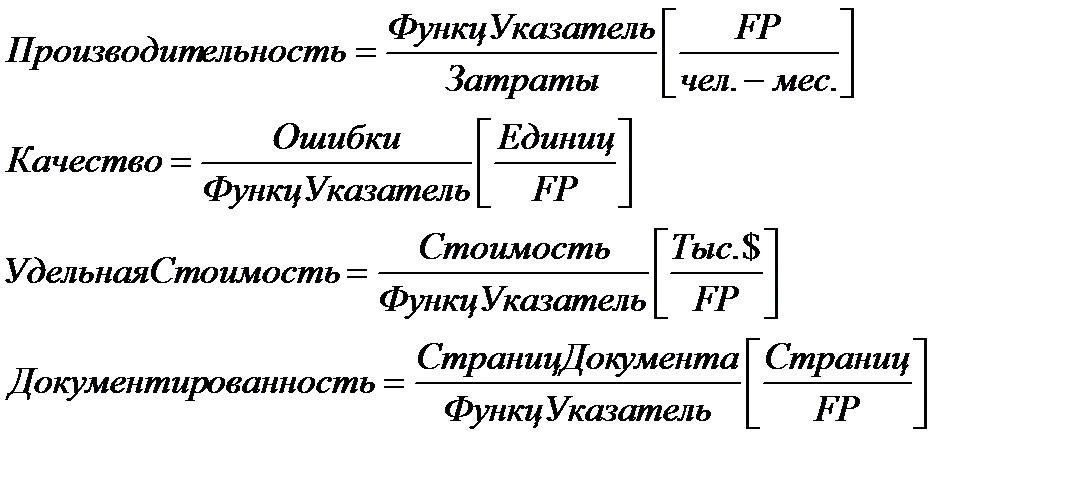
Достоинства функционально-ориентированных метрик:
1. Не зависят от языка программирования.
2. Легко вычисляются на любой стадии проекта.
Недостаток функционально-ориентированных метрик: результаты основаны на субъективных данных, используются не прямые, а косвенные измерения.
Выполнение оценки проекта на основе LOC- и FP-метрик
Цель этой деятельности — сформировать предварительные оценки, которые позволят:
· предъявить заказчику корректные требования по стоимости и затратам на разработку программного продукта;
· составить план программного проекта.
При выполнении оценки возможны два варианта использования LOC- и FP-данных:
· в качестве оценочных переменных, определяющих размер каждого элемента продукта;
· в качестве метрик, собранных за прошлые проекты и входящих в метрический базис фирмы.
Обсудим шаги процесса оценки.
Шаг 1. Область назначения проектируемого продукта разбивается на ряд функций, каждую из которых можно оценить индивидуально:
f1, f2,…, fn
Шаг 2. Для каждой функции fi планировщик формирует лучшую LOCлучшi (FPлучшi), худшую LOCхудшi (FPхудшi) и вероятную оценку LOCвероятнi (FPвероятнi). Используются опытные данные (из метрического базиса) или интуиция. Диапазон значения оценок соответствует степени предусмотренной неопределенности.
Шаг3. Для каждой функции fi в соответствии с β-распределением вычисляется ожидаемое значение LOC- (или FP-) оценки:

Шаг 4. Определяется значение LOC- или FP-производительности разработки функции.
Используется один из трех подходов:
1. для всех функций принимается одна и та же метрика средней производительности ПРОИЗВср, взятая из метрического базиса;
2. для i-й функции на основе метрики средней производительности вычисляется настраиваемая величина производительности:
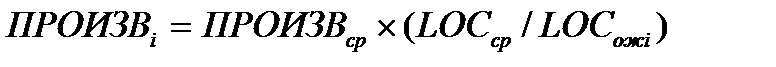
где LOCcp — средняя LOC-оценка, взятая из метрического базиса (соответствует средней производительности);
3. для i-й функции настраиваемая величина производительности вычисляется по аналогу, взятому из метрического базиса:

Первый подход обеспечивает минимальную точность (при максимальной простоте вычислений), а третий подход — максимальную точность (при максимальной сложности вычислений).
Шаг 5. Вычисляется общая оценка затрат на проект:
для первого подхода

для второго и третьего подходов
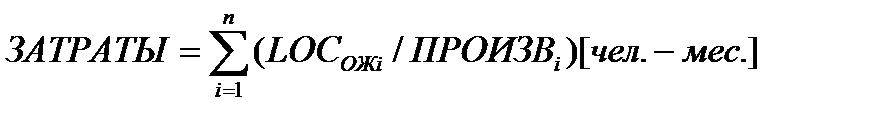
Шаг 6. Вычисляется общая оценка стоимости проекта:
для первого и второго подходов
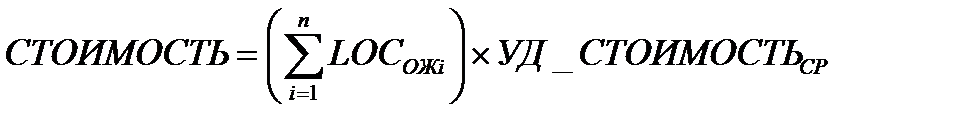
где УД_СТОИМОСТЬср — метрика средней стоимости одной строки, взятая из метрического базиса.
для третьего подхода
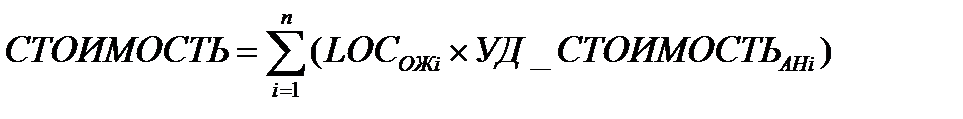
где УД_СТОИМОСТЬанi — метрика стоимости одной строки аналога, взятая из метрического базиса.
Конструктивная модель стоимости (COCOMO II).
Ввел в 1995 году Барри Боэм.
В состав COCOMO II входят:
· модель композиции приложения;
· модель раннего этапа проектирования;
· модель этапа пост-архитектуры.
Для описания моделей COCOMO II требуется информация о размере программного продукта. Возможно использование LOC-оценок, объектных указателей, функциональных указателей.
Модель композиции приложения
Модель используется на ранней стадии конструирования ПО, когда:
· рассматривается макетирование пользовательских интерфейсов;
· обсуждается взаимодействие ПО и компьютерной системы;
· оценивается производительность;
· определяется степень зрелости технологии.
Модель композиции приложения ориентирована на применение объектных указателей.
Объектный указатель – средство косвенного измерения ПО, для его расчета определяется количество экранов (как элементов пользовательского интерфейса), отчетов и компонентов, требуемых для построения приложения. Каждый объектный экземпляр относят к одному из трех уровней сложности (по таблице). После определения сложности количество экранов, отчетов и компонентов взвешивается в соответствии с таблицей. Количество объектных указателей определяется перемножением исходного числа объектных экземпляров на весовые коэффициенты и последующим суммированием промежуточных результатов.
Для учета реальных условий разработки вычисляется процент повторного использования программных компонентов %REUSE и определяется количество новых объектных указателей NOP:
NOP=(Объектные указатели)*[(100-%REUSE)/100].
Для оценки затрат, основанной на величине NOP, надо знать скорость разработки продукта PROD. Он определяется по таблице, учитывающей опытность разработчиков.
ЗАТРАТЫ = NOP/PROD [чел.-мес.],
где PROD – производительность разработки, выраженная в терминах объектных указателей.
Модель раннего этапа проектирования
Модель раннего этапа проектирования используется в период, когда стабилизируются требования и определяется базисная программная архитектура. Основное уравнение этой модели имеет следующий вид:
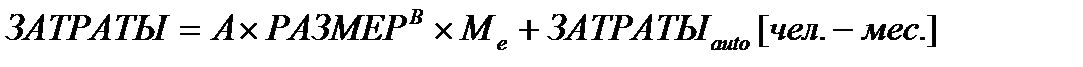
где
· масштабный коэффициент А = 2,5;
· показатель В отражает нелинейную зависимость затрат от размера проекта (размер системы РАЗМЕР выражается в тысячах LOC);
· множитель поправки Ме зависит от 7 формирователей затрат, характеризующих продукт, процесс и персонал;
· слагаемое ЗАТРАТЫauto отражает затраты на автоматически генерируемый программный код.
Значение показателя степени В изменяется в диапазоне 1,01...1,26, зависит от пяти масштабных факторов Wi (принимают 6 значений: от очень низкой (5) дло сверхвысокой (0)) и вычисляется по формуле

Множитель поправки Ме зависит от набора формирователей затрат (по таблице).
Для каждого формирователя затрат определяется оценка (по 6-балльной шкале), где 1 соответствует очень низкому значению, а 6 — сверхвысокому значению. На основе оценки для каждого формирователя по таблице Боэма определяется множитель затрат ЕМi. Перемножение всех множителей затрат формирует множитель поправки:
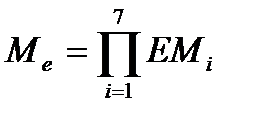
Слагаемое ЗАТРАТЫauto используется, если некоторый процент программного кода генерируется автоматически. Поскольку производительность такой работы значительно выше, чем при ручной разработке кода, требуемые затраты вычисляются отдельно, по следующей формуле:
 ,
,
где
KALOC — количество строк автоматически генерируемого кода (в тысячах строк);
AT — процент автоматически генерируемого кода (от всего кода системы);
ATPROD — производительность автоматической генерации кода.
Сомножитель AT в этой формуле позволяет учесть затраты на организацию взаимодействия автоматически генерируемого кода с оставшейся частью системы.
Далее затраты на автоматическую генерацию добавляются к затратам, вычисленным для кода, разработанного вручную.
Модель этапа постархитектуры
Модель этапа постархитектуры используется в период, когда уже сформирована архитектура и выполняется дальнейшая разработка программного продукта.
Основное уравнение постархитектурной модели является развитием уравнения предыдущей модели и имеет следующий вид:
 ,
,
где
коэффициент K~req учитывает возможные изменения в требованиях;
показатель В отражает нелинейную зависимость затрат от размера проекта (размер выражается в KLOC), вычисляется так же, как и в предыдущей модели;
в размере проекта различают две составляющие — новый код и повторно используемый код;
множитель поправки Мр зависит от 17 факторов затрат, характеризующих продукт, аппаратуру, персонал и проект.
Изменчивость требований приводит к повторной работе, требуемой для учета предлагаемых изменений, оценка их влияния выполняется по формуле

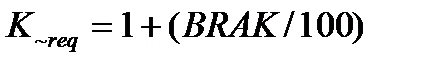 ,
,
где BRAK — процент кода, отброшенного (модифицированного) из-за изменения требований.
Размер проекта и продукта определяют по выражению
РАЗМЕР = PA3MEPnew + PA3MEPreuse [KLOC],
где
PA3MEPnew — размер нового (создаваемого) программного кода;
PA3MEPreuse — размер повторно используемого программного кода.
Дата добавления: 2015-04-18; просмотров: 202053; Мы поможем в написании вашей работы!; Нарушение авторских прав |