КАТЕГОРИИ:
АстрономияБиологияГеографияДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРиторикаСоциологияСпортСтроительствоТехнологияФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Проектирование БД как сжатие информации.
Какую структуру БД считать оптимальной? Не смотря на серьезные сложности как теоретического, так и практического характера, центральной руководящей идеей проектирования служит очевидный
Основной принцип– не дублируй информацию (за очевидным исключением ключей-ссылок)! Каждая ее часть должна храниться в одном, и только одном месте - таблице, определение которой согласовано с логикой задачи. Сведения, которые могут быть выведены (вычислены) – не информация и не должны храниться вообще.
Кроме очевидной цели компактного хранения (а БД - это большие хранилища данных, которые могут содержать миллионы записей; при таких объемах выигрыш или проигрыш в один символ при хранении каждой записи может оказаться весьма ощутимым), недопустимость дублирования вызвана и не менее важной причиной сложности модификации - при наличии дублирования, при коррекции одной копии необходимо корректировать и все остальные (а для этого, как минимум, программист должен вспомнить - а где же они все же расположены?)
Вернемся к примеру с жителями. При ожидаемом реальном наличии большого числа "пересечений" в полях таблицы ДОМА (т.е. достаточно большого числа повторений названий городов и улиц), можно
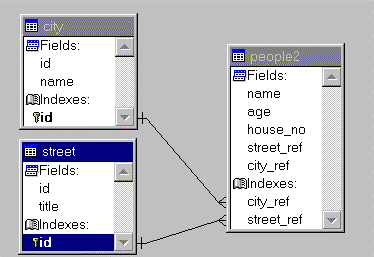
а) завести справочные (кодировочные) таблицы
УЛИЦЫ={<код_улицы, название_улицы>} и
ГОРОДА={<код_города,название_города>},
сопоставляющую длинным названиям улиц и городов некоторые краткие коды с тем, чтобы иметь возможность хранить в таблицах ДОМА и ЛЮДИ более краткие ключи вида
<номер_дома, код_улицы, код_города>
 |
или же
б) связать улицы с номерами имеющихся на них домов, а города – с названиями имеющихся в нем улиц, определив структуру введенных таблиц следующим образом
ЛЮДИ={<код_дома,...(другие атрибуты людей)>}
ДОМА={<код_дома, номер_дома, код_улицы,... (другие атрибуты домов)>},
УЛИЦЫ={<код_улицы, название_улицы, код_города>},
ГОРОДА={<код_города, название_города>},

Очевидно, что осуществив разбиение (декомпозицию) информации о связи между домами и улицами, а также улицами и городами (которую мы намеревались первоначально хранить в таблице ДОМА) и вынеся ее в отдельные таблицы УЛИЦЫ и ГОРОДА, мы получили новые связи “один-ко-многим” между таблицами УЛИЦЫ-ДОМА и ГОРОДА-УЛИЦЫ.
Приведенный пример показывает, что
соображения физической эффективности хранения и обработки данных могут потребовать уточнения (декомпозиции), но никак - не ломки! - начальной логической схемы. (Вспомним наш старый принцип - семантика основа прагматики!)
Будем считать в дальнейшем, что мы приняли последний вариант решения. Почему? Очевидно, такое сжатие будет тем более эффективным, чем больше его “коэффициент” - среднее количество дочерних записей, приходящихся на одну родительскую запись. В худшем случае – связи “один-ко-одному” – мы в реальности лишь увеличим объем хранимой информации за счет введения избыточных кодов. Таким образом, (весьма нелегкая в практическом воплощении) стратегия определения структуры БД должна преследовать цель максимизации коэффициента сжатия.
Что мы делали, с точки зрения математики?
Соединением (композицией) двух таблиц (отношений) PTÌX1´…´PK´… ´Xn , CTÌ Y1´…´FK´… ´Ym по связи PK,FK называют таблицу
JÌ X1´…´PK´… ´Xn´ Y1´…´FK´… ´Ym,
J={<x1,…,pk,…xn,y1,…,fk,…ym>: <x1,…,pk,…xn>Î PT & <y1,…,fk,…ym>Î CT & pk=fk}
(слегка различные определения получим, если оставить в J лишь одно из равных значений pk,fk или исключить оба значения)
Декомпозиция – разбиение таблицы на две, композицией которых по некоторому отношению она является.
Теперь можно переформулировать наш основной принцип.
- Осуществляй декомпозицию (с учетом кардинальности связи)
И все-таки, пока наш совет слишком общий для практического применения. Когда, в каких случаях можно и нужно осуществлять декомпозицию, какова стратегия декомпозиции?
Нормализация БД.
Теоретическим фундаментом такой стратегии является понятие нормальной формы таблиц и, соответственно, интерпретация процесса проектирования как последовательного приведения к нормальным формам. Считается, что практически приемлемый результат дает приведение к первым 3 нормальным формам.
Первая н.ф. уточняет определение таблиц. Все поля таблиц должны быть уникальными атомами, а все содержательные отношения должны определяется с помощью внешних связей таблиц.
Под атомарностью имеется в виду неделимость логическая, т.е. зависящая от постановки задачи. Скажем, фамилия – строка символов, но она в большинстве случаев она неделима для нас как логическая единица, в то время как адрес – делим. Уникальность также понимается в логическом смысле. Поля могут быть одного типа, но они должны описывать разные атрибуты моделируемого объекта (в терминологии реляционной теории – принадлежать к разным доменам).
В отличие от изначального для реляционного подхода понятия отношения, таблицы как произвольного множества записей, в основе 2 и 3 нормальных форм (н.ф.) лежит понятие таблично задаваемой функции (графика, соответствия), взгляд на таблицу как график зависимости значений не ключевых полей от значений ключевых.
Пусть R – таблица, R Í T1´ … ´ Tn. Поле Ti зависит от поля Tj, если
" r1,r12Î R (r1i = r2i à r1j = r2j).
Аналогично определяется зависимость группы полей от группы полей (и выражений). По определению, все поля зависят от ключа.
Вторая н.ф. требует, чтобы в случае составных ключей ее аргументом служил весь ключ, а не отдельные входящие в него поля; т.е. для любой части ключа и любой части записи не существовало зависимости.

Третья - то, чтобы ее аргументом служил только ключ, т.е. значения каждого не ключевого поля не зависели от значений никаких других полей, кроме ключевых. (В противном случае говорят о транзитивной зависимости)
| |||||
 | |||||
 |
Проиллюстрируем процесс нормализации на примере базы данных, описывающий факты купли-продажи: «Покупатели (Customer) делают заказы (Order) на товары (Product) продавцам (Employee)”
Первая нормальная форма. Атомарность.
Положим, что в контексте ситуации нас интересуют лишь следующие их характеристики «сущностей» Customer, Employee, Order и Product
Customer – cName (имя покупателя),
Employee - eName (имя продавца)
Order – oTotal (сумма заказа), oDate (дата заказа)
Product – pName (название товара), pPrice (цена товара), pAmount (количество проданного покупателю товара)
Положим также, что каждая из основных сущностей имеет некоторый естественно определяемый первичный ключ:
Cust_Id – скажем, номер паспорта покупателя
Emp_Id – табельный номер продавца
Order_Id – учетный номер заказа
Prod_Id – артикул товара
Изначально, имеем сложное 4-арное отношение между сущностями Customer, Employee, Order и Product, что соответствует самому простой, весьма далекой от оптимальной “плоской” структуре БД, состоящей из единственной таблицы.
 |
Формально - нужно осуществить его декомпозицию (разбиение) на совокупность бинарных отношений, что мы и могли бы сделать, нормализуя исходную БД. Естественнее однако, попытаться определить в логических терминах отношения между сущностями. Если не формальное определение, то смысл последних явно следует из постановки задачи.
Customer/Order – Покупатель делает заказ
Employee/Order – Продавец принимает/исполняет заказ
Order/Product – Заказ состоит из (включает в себя) набора товаров
(отметьте – все отношения “один-ко-многим”)
Все остальные отношения между сущностями явно вторичны, косвенны, не бинарны – скажем отношение продавец/покупатель явно подразумевает наличие заказа. (Здесь и далее мы стараемся делать самые слабые допущения относительно предметной области. Нетрудно представить ситуацию, когда присутствуют и другие отношения между сущностями. Скажем, в данной фирме каждый покупатель может быть “прикреплен” к конкретному продавцу, что соответствуют наличию прямой связи Employee/Customer).
Первые два отношения нетрудно реализовать добавлением в таблицы Customer и Employee ключевых полей CustId и EmpId, и добавлением соотвествующих полей - внешних ключей CustRef и EmpRef в таблицу Order. Ситуация с отношением Order/Product чуть сложнее. То, что сущность/понятие «заказ» включает в себя несколько экземпляров сущностей «товар» провоцирует на то, что структура таблицы Order должна включать в себя несколько ссылок на таблицу Product – скажем, ProdRef1,…, ProdRefn. Технически, это возможно, если известна явная константа – максимальное число товаров в заказе – скажем, не более 3. Но с точки зрения 1 НФ использование таких неявных отношений “один-ко-многим” недопустимо.

Замечание. Нормальные формы – лишь ориентир при проектировании. Реальная практика часто требует более тонкой классификации отношений и учета кардинальности связей. “Статичные” связи вида 1:Const и даже Const1:Const2 нередко на практике закладываются в определение таблиц. Пример – поквартальные или помесячные сводки – соответственно, связи вида 1:4 и 1:12. Категорически запрещается лишь фиксировать в структуре таблицы лишь отношения с переменной кардинальностью.
“Лобовой” способ удовлетворить 1РФ – превратить статичную структуру полей в динамическую структуру записей, переструктуриров таблицу Orders так, чтобы «дублирующие сущность» поля Product1,Product2,… стали записями этой таблицы:

Однако, это приводит к тому, что теперь группа полей зависят от OrderId (собственно заказа), а другая часть – от OrderId,ProdId (отдельного пункта заказа), что противоречит 2НФ. Нужно оставить лишь поля – атрибуты самого заказа, выделив все лишнее – атрибуты экземпляра товара, пункта заказа – в отдельную таблицу. Это заставляет нас выделить явно отношение включения между заказом и экземляром товара (OrderItem).

Наконец, посмотрим на таблицу oItem. Является ли пара Order_Ref, Prod_Id первичным ключом, т.е. могут ли в одном заказе одинаковые товары? Положим, что да. Для идентификации пункта добавим поле item_no – номер пункта заказа. Тогда Order_Ref, Item_No – первичный ключ, он определяет товар (снова - в том лишь смысле, что для данного заказа и номера, существует единственный товар этого заказа с таким номером). Но цена товара определяется самим товаром, т.е. Prod_Id, не входящим в первичный ключ. Нарушено требование 3 н.ф. Выносим отношение Prod_Id/Price в отдельную таблицу Product и добавляем связь между oItem и Product. Логически, это связь - отношение принадлежности между товаром и экземпляром товара.
Скуфе 
Модификация БД. Процедурные и декларативные СУБД.
Нарушения целостности.
 Итак, если логически реляционные БД – совокупность таблиц, связанных отношениями, декомпозиция некоторого отношения R на бинарные, то, с точки зрения реализации – это просто набор таблиц (файлов записей).
Итак, если логически реляционные БД – совокупность таблиц, связанных отношениями, декомпозиция некоторого отношения R на бинарные, то, с точки зрения реализации – это просто набор таблиц (файлов записей).
Не удивительно поэтому, что с точки зрения реализации, модификация (преобразование состояния) БД – преобразования таблиц, сводящиеся в свою очередь, к преобразованиям записей соответствующих файлов. В процедурно-реляционно, «навигационных» языках (например, в языках популярного семейства языков СУБД, ориентированных на «малые» БД для персональных компьютеров xBase-dBase-FoxPro) алгоритмы преобразования записей таблиц осуществляются программистом, в декларативно (“собственно”) реляционных языках (пример – язык SQL, изначально – командный язык мэйнфреймов, «больших компьютеров» фирмы IBM) программист задает лишь спецификацию таких преобразований.
 | |
 | |
 |
С точки зрения реализации, преобразование БД есть либо
- добавление (insert, append)
- удаление (delete)
- преобразование/модификация значения (replace, update)
Соотвественно, в процедурных языках БД присутствуют команды добавления, удаления записей и модификации значений полей записей, в декларативных языках – команды добавления таблицы к таблице, удаления подтаблицы и изменения значений в (под)таблице.
Конкретную структуру и синтаксис команд классического декларативного языка мы рассмотрим ниже, сейчас отметим более существенный момент.
Проблема.
Очевидно, любая модификация БД должна сохранять ее семантику (т.е. отношение R), преобразовывать одно корректное состояние базы в другое. Реализация преобразований допускает некорректные состояния. В этом случае говорят о нарушении целостности данных БД.
Разумеется, это не есть специфическая для СУБД проблема, но именно здесь она преобретает наибольшую остроту. В отличие от процедурного программирования, СУБД изначально ориентированы на данные и корректность данных имеет здесь наивысший приоритет.
Нарушение целостности может происходить по 2 причинам. Первая из них связана с очень слабым аппаратом описания типов данных. Это может проявляться в следующих нарушениях целостности:
0) Нарушения “уровня столбца” (пример – уникальность, но не упорядоченность!)
1) Нарушения “уровня поля”, неточное описание доменов - областей допустимых, с точки зрения логики предметной области, значений полей.
Пример. Описание прямоугольника R={<x,y>: x Î [1,3] & y Î[1,2]} в качестве таблицы (именованного отношения) как подмножества D2 (D – множество вещественных чисел) – что верно, но не точно, поскольку технически допустима, например, запись {xà0,yà0}
 |
2) Нарушения “уровня записи”. Неточное описание таблицы как отношения, взаимосвязи значений полей.
Пример. Описание круга R={<x,y>: x2+ y2£1} как подмножества D2
 |
Отметьте – ситуация действительно отличается от 1). Даже точное описание доменов полей – R Ì [-1,1] 2- не спасает от возможных ошибок.
Принятое решение – описывать таблиц более точно, за счет добавления к определению таблиц предикатов, ограничивающих множества допустимых состояния полей и записей. Такие предикаты называют правилами допустимости (значений)– validation rules.
Нарушения “уровня связей”. Второй тип ошибок следует непосредственно из реализации. Команды СУБД преобразуют таблицы, а не связи, в то время как любое нетривиальное преобразование предполагает согласованное преобразование двух и более таблиц. Корректное изменение состояния таблицы не означает корректного изменения состояния БД.
Скажем, логическое действие “удалить из БД информацию о данном заказе” означает не только удаление соответствующей записи из таблицы Orders, но и удаление ее дочерних записей (пунктов заказа) из таблицы Items и даже, возможно, удаление информации о покупателе, сделавшем этот заказ в случае, если в БД больше нет информации о его заказах.
Данные – не только область допустимых значений. Описание данных предполагает и описание класса допустимых преобразований.
Удивительно, насколько это фундаментальное и общепринятое по отношению к типам данных положение с трудом проникает в область БД - по существу, частного случая типа данных. По всей видимости, в практике современных СУБД пока не делалось серъезной попытки анализа и классификации класса семантических преобразований, сохраняющих декомпозицию многоместных отношений (но – см. далее понятие трансакции). Но эволюция в нужном направлении очевидна.
В современных СУБД рассматривается класс преобразований двух связанных отношением таблиц, сохраняющих ссылочную целостность (referential integrity).
Преобразование двух связанных отношением “один-ко-многим” таблиц не сохраняет ссылочную целостность, если после его применения в дочерней таблице остаются “сироты”, т.е. записи с несуществующим в родительской таблице значением внешнего ключа.
Различают несколько стандартных типов сохранения ссылочной целостности.
К "операционной" эволюции реляционных БД. Технология клиент-сервер.
Итак, с точки зрения изначальной логики строения информации,база данных (БД)естьформальная модель некоторой предметной области в виде совокупности таблиц, связанных отношениями.
| |
С точки зрения технологии "клиент-сервер", это традиционное определение нуждается в существенном добавлении - отражения логики практически возможного и логически допустимого изменения данных, реализуемой с помощью хранимых,вместе со значениями данных, процедур.
Эта точка зрения отражает еще более фундаментальный сдвиг в методологии программирования, нашедший на сегодня свое наиболее полное выражение в концепции абстрактного типа данных (или - класса, в объектно-ориентированном программировании, компонента в COM-).
 |
Таким образом, понятие данных приобретает существенно динамический характер. С другой стороны, понятие абстрактного типа данных статично в том смысле, что система типов должно быть предварительно определена, хотя бы в виде абстрактной схемы, до разработки конкретных алгоритмов, с учетом всех возможных в дальнейшем случаев их использования. Такая существенная перемена приоритетов выдвигает на передний, центральный план этапы концептуального анализа и проектирования, с использованием соответствующих логико-математических методов. По статистическим оценкам, соотношение между этапами проектирования и собственно кодирования составляет около 80/20 - пропорция, обратная по отношению к традиционным методам!
Для того, чтобы в процессе модификации - а именно, вставки (insert), обновления (update) и удаления (delete) записей - БД не перестала быть целостной, т.е. не перестала адекватно отражать реальное содержание предметной области, необходимо выполнение следующих требований - правил целостности, или "бизнес-правил":
- таблицы БД не должны содержать нереальных данных, которые могут появиться как следствие ошибок программ обработки БД или некорректного ввода. Для этого в определение таблиц БД добавляют правила проверки (validation rules) значений поля или группы полей, определяющие необходимые условия их корректности;
так, например, значение поля номер_дома в таблице ДОМА должен принадлежать некоторому допустимому интервалу натуральных чисел – скажем, от 1 до 1000 (при более точном моделировании мы могли бы отражать встречающиеся в реальности номера домов вида натуральное-буква и сформулировать более сложное условие проверки корректности значения поля);
В том - крайне нежелательном и опасном! - случае, когда задача моделирования подразумевает наличие связи между таблицами, но фактически некоторая запись дочерней таблицы не ссылается ни на одну запись родительской таблицы (т.е. содержит отсутствующий в родительской таблице значение ключа), то такую запись называют сиротой (orphan). По соглашению, запись с неопределенным явно, т.е. равным NULL, ключом сиротой не считается.
Так, в нашем примере запись в таблице ЛЮДИ будет сиротой, если она содержит ссылку на не существующий адрес дома – отсутствующее в таблице ДОМА значение поля КодДома. Запись со значением ссылки NULL ("временно не имеющий места жительства") сиротой не будет.
- БД должна удовлетворять условию ссылочной целостности (referential integrity), т.е. в таблицы БД, - в результате тех же причин - не должны попадать записи-"сироты". Следовательно, модификация связанных таблиц должна быть согласованной. К наиболее простым и популярным вариантам такого согласования относят ситуации, когда модификация записи родительской таблицы является
а) каскадной (cascades), т.е. продолжается на соответствующие записи дочерней таблицы;
b) нулевой (nulls), т.е. устанавливающей ключи дочерних записей в NULL;
c) ограниченной (restricted), т.е. возможной и исполняемой лишь в тех случаях, когда у нее нет ни одной дочерней записи.
Как и правила проверки, варианты сохранения ссылочной целостности БД также являются частью ее определения. Обеспечивающие целостность стандартные хранимые процедуры называются триггерами.[2]Разумеется, более сложные варианты согласования модификации двух и более таблиц могут потребовать реализации соответствующих пользовательских процедур-триггеров.
Так, в нашем примере наиболее естественно принять ограниченный вариант удаления – информация о доме не может быть удалена, пока таблица ЛЮДИ содержит хотя бы одну запись о человеке, в этом доме проживающем, и каскадный вариант модификации значений – изменение первичного ключа в любой записи таблицы ДОМА (т.е. одного из полей номер_дома, код_улицы, код_города) должно автоматически изменять атрибуты соответствующих записей дочерней таблицы ЛЮДИ.
С точки зрения реляционного подхода, все команды СУБД рассматриваются как преобразователи одной или нескольких таблиц, результатом которых снова является таблица (новая или обновленная старая):
T := y(T1,…,Tn)
à (Стандартный) SQL – фактически, язык, состоящий из одних присваиваний.
К командам модификации (редактирования таблиц) БД относят команды вставки, удаления и изменения групп записей таблицы.
Дата добавления: 2015-01-29; просмотров: 313; Мы поможем в написании вашей работы!; Нарушение авторских прав |