КАТЕГОРИИ:
АстрономияБиологияГеографияДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРиторикаСоциологияСпортСтроительствоТехнологияФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Quot;Понимание" текста на естественном языке
Многие процессы информационной деятельности: поиск информации, ее отбор, аналитико-синтетическая переработка, распространение – все это процессы, связанные с чтением, пониманием (извлечением смысла) и формулированием текста на естественном языке. Вот почему автоматизация этих процессов занимает важное место при разработке новых информационных технологий. Впервые информационные работники вплотную столкнулись с этой проблемой, когда в начале 50-х годов начались интенсивные эксперименты по машинному переводу. По этому поводу существуют разные мнения, о чем говорилось в лекции об информационных системах.
Моя позиция заключается в том, что адекватный перевод текстов с одного естественного языка на другой – задача, не имеющая однозначного решения. Всегда можно получить несколько разных переводов одного и того же текста, в отношении которых допустимо говорить, что они достаточно близки к оригиналу и стилистически корректны, причем степень того и другого не поддается измерению. Подтверждение этой мысли можно найти, если рассматривать эти переводы в диахронии, т. е. на протяжении некоторого времени. Оригинал художественного произведения всегда остается неизменным, а перевод быстро устаревает и нуждается в обновлении. А раз так, то и формализовать эту задачу для ее машинного решения можно лишь в зависимости от формализованности оригинального текста.
Обсуждая возможность адекватного перевода, полезно представить мысленно некоторую шкалу, на которой расположены разные типы текстов различной степени переводимости. На левом краю шкалы находятся поэтические тексты, в отношении которых термин "перевод" применяется условно, поскольку здесь речь идет о переложении поэтических образов, т. е. о сочинении новой поэзии. Продвигаясь по шкале вправо, мы последовательно встретимся с художественной прозой, научными и деловыми бумагами, личной и ведомственной перепиской. Наконец, на правом краю шкалы мы найдем некоторые типы текстов, однозначно передающихся из одного естественного языка в другой. Это различного рода юридические формулы (включая патентные), номенклатурные перечни, транскрибируемые или транслитерируемые названия и имена. Очевидно, что возможность автоматизации перевода и вообще переработки текста будет возрастать по этой шкале слева направо.
Нас, в данном случае, интересуют те типы текстов, которые занимают довольно большое пространство в центре шкалы и которые по меткому выражению покойного академика А. П. Ершова называют "деловой прозой". Он считал, что деловая проза отражает производственные отношения людей и является таким фрагментом естественного языка, который может быть "воспринят" компьютером.
Это убеждение он основывал на том, что данные отношения людей более строго регламентированы, чем другие, что деловая проза используется в модельных ситуациях, которые ведут к ее формализации. "Стихийно реализуемая, – писал он, – но властно диктуемая сутью дела потребность обеспечить быстрое и точное взаимопонимание наградила деловую прозу жесткими средствами выражения, экономичностью и другими полезными для человека и машины свойствами". Ясно, что большая часть публицистики, научных и административных документов написана деловой прозой.
В последние десятилетия успехи лингвистики и логики во многом продвинули наше понимание сложностей машинного перевода, а достижения электронной техники сделали возможными практические системы, которые работают в промышленном режиме (обычно с предварительной подготовкой оригинального текста и последующим редактированием машинного перевода человеком).
Но все же камнем преткновения автоматизированной обработки текста, которая лежит в основе диалога человека с компьютером на естественном языке, является необходимость для понимания этого текста владеть определенными знаниями экстралингвистической (т. е. не содержащейся в тексте) информацией и логическим мышлением (т. е. способностью к логическому выводу и правдоподобным рассуждениям).
Мы уже говорили, что пятое поколение вычислительных машин, с внедрением которых связывали новые революционные изменения в информационной технологии, авторы проекта представляли как компьютеры, ведущие диалог на естественном языке. Многие лингвисты сомневаются в правомерности такой формулировки. Не входя слишком глубоко в существо проблемы, попытаемся вникнуть в представления специалистов о тех видах лингвистического анализа, которые, собственно, и являются машинным "пониманием" естественного языка. Одна из первых трудностей заключается в неоднозначности многих его выражений, даже когда речь идет о языке деловой прозы.
Выделяют пять типов такой неоднозначности: лексическую, структурную, "глубинную", семантическую и прагматическую.
Лексическая неоднозначность возникает из-за полисемии большого числа слов, включая специальные термины. Нам удается устранять эту неоднозначность на уровне человеческого интеллекта, так как, зная контекст, всегда понимаешь, идет ли речь о ключе гаечном, от двери или том, который бьет из-под земли. При информационном поиске нам помогает в этом тезаурус, где слова с разными значениями маркируются. Однако для различения этих значений в машине часто приходится прибегать к трудоемким (и не всегда дающим правильный результат) статистическим процедурам.
Структурная неоднозначность – это, прежде всего, возможность разного синтаксического членения предложения. Например, фразу "Наблюдения над языком маленьких детей" можно понять двояко: кто-то наблюдает за языком детей или дети ведут наблюдения над языком, в зависимости от того, относится ли слово "детей" к слову "язык" или к слову "наблюдения".
Неоднозначность на уровне глубинной структуры содержится во фразе "Этот текст улучшить нельзя": либо потому, что он совершенен, либо потому, что безнадежно плох (примеры Ю. Д. Апресяна). Сравнивая две фразы "Каша готова к обеду" и "Цыплята готовы к обеду", мы усматриваем двусмысленность второй из них, поскольку знаем, что цыплят можно и кормить и есть.
Семантическая неоднозначность в речи часто возникает из-за незнания ситуации. Вам говорят: "Купите автомобиль", и это может означать, что вы выбираете между автомобилем и мотоциклом, а может быть просто не знаете, куда потратить деньги. "Человек упал, разбил окно, повредил себе руку" – все эти действия могли быть и нечаянными и намеренными. В зависимости от этого перевод фразы на другой язык и представление ее в машине будут разными.
Прагматическая неоднозначность иллюстрируется фразой "Он уронил карандаш на стол и сломал его". Для человеческого опыта в ней нет неясности, поскольку мы понимаем, что сломался карандаш, но машине это не очевидно. При переводе на другие языки "карандаш" и "стол" могут оказаться словами разного грамматического рода (например, в испанском и французском первое мужского рода, а второе женского), и это окажется существенным.
Для иллюстрации лингвистического и логического анализа, необходимого при машинном «понимании» языка, воспользуемся моделью американского филолога Т. Винограда (Стэнфордский университет),на идеях которого основывается наше изложение. Реализация этой модели (рис. 14 ) требует сложных компьютерных программ баз данных и баз знаний, содержащих различные словари и правила. Предположим, что в машину введена фраза: Технологии будут развиваться по законам, которые мы поняли очень давно. Если она введена с голоса, то для нее должен быть выполнен фонетический анализ, если же вводится письменный текст (с клавиатуры или сканера), то программа начинается с морфологического анализа. Целью первого является распознавание и идентификация фонем, целью второго – установление основных форм слов и их флексий. На третьем этапе проводится лексический анализ, в результате которого образуется последовательность слов, соотнесенных с частями речи и их морфологическими характеристиками (число, падеж и т. п.). На четвертом этапе осуществляется синтаксический анализ фразы – грамматический разбор предложения, – который дает синтаксическую ее структуру (на рисунке она показана в виде дерева). Однако эта поверхностная структура не всегда однозначна, как мы уже убедились на примерах. Поэтому требуется еще анализ глубинной структуры (на рисунке не показанный).
Дальнейшие этапы машинного понимания текста переводят его синтаксическую структуру в логическую, которая позволяет применить процедуры логического вывода и рассуждений. Существуют различные формы семантических анализаторов для кодирования смысла языковых выражений. В данной модели используется исчисление предикатов.
После семантического анализа логическая структура предложения записывается цепочкой логических символов, которые могут быть прочитаны следующим образом:
Существуют такие x, y, z, t0, t1, t2,
что x есть технология,
y есть закон,
z есть произносящий фразу, который понял y в момент t2 ,
t0 есть момент произнесения,
t1 наступит после момента произнесения t0 ,
x развивается по y в момент t1 ,
t2 был задолго до t0 .
В ходе прагматического анализа определяется, в частности, что именно известно о переменных. Например, x – связанная квантором переменная. Она утверждает существование чего-то, но не указывает на определенный объект. Другими словами, технологии в данном случае это технологии вообще, а не какие-либо конкретные технологии. Точно так же переменная y есть неопределенный объект, задаваемый контекстом. Переменная z тоже остается не полностью определенной, поскольку местоимение мы может означать авторов высказывания, авторов и читателей, профессионалов данной области, вообще людей данного поколения. Целью машинного понимания языка является возможность диалога с машиной, в ходе которого компьютер мог бы давать логически осмысленные ответы на вопросы пользователя или же преобразовывать команды в определенные действия, учитывающие реальность. Эту задачу решает последний этап анализа, обозначенный на рис. 14 как «Рассуждения».

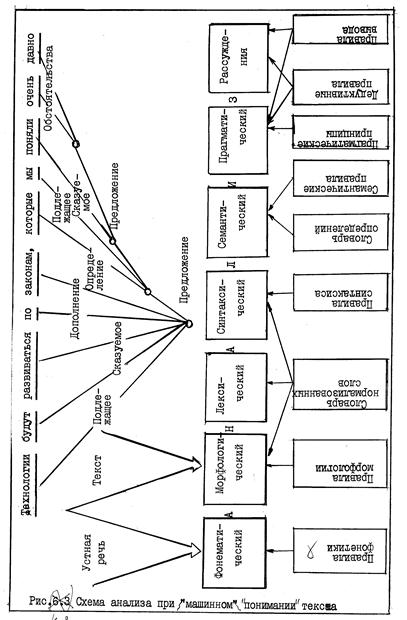
Каким образом, например, машина, воспринявшая нашу фразу, будет отвечать на вопрос: «Понимаем ли мы законы, по которым будет развиваться реферирование?» Для того, чтобы ответить на этот вопрос, компьютер должен знать, что реферирование есть процесс, относящийся к информационной технологии. Такое знание можно изобразить формулой исчисления предикатов: «Все, что есть реферирование, есть технология».
Есть и другие достаточно эффективные способы введения знаний в машину, такие как семантические сети, фреймы. Можно, например, ввести в машину семантическую сеть, в которой все виды технологий, включая и информационную, и все их разновидности будут связаны определенными отношениями (род–вид, часть–целое и т. п.). По такой сети можно автоматически определить, что реферирование есть часть, или вернее, один из процессов информационной технологии. Таким образом, в данной ситуации компьютер сможет дать правильный ответ на заданный ему вопрос.
Однако трудность реального представления знаний в машине заключается в многообразии конкретных ситуаций, от которых зависит понимание человеком текстов на естественном языке. В нашем примере из контекста нельзя понять, что означает выражение «очень давно», хотя информационные работники знают, что понимание некоторых законов информационной технологии пришло благодаря интенсивным исследованиям научных коммуникаций в середине 60‑х гг. ХХ в.
Подобным же образом и выражение «будут развиваться» означает не столько будущее время, сколько продолженное действие. Можно привести много других примеров, когда фраза на естественном языке, вполне понятная человеку в конкретной ситуации, требует специальных приемов интерпретации для ее машинного понимания.
Во многих научных коллективах разрабатываются методы перевода с естественного языка на язык математической логики. Они необходимы для глубокого семантического анализа во многих автоматизированных информационных системах.
В проведении исследований важное место занимает анализатор, осуществляющий перевод синтаксического «дерева» в формулы информационно‑логического языка. На каждом шаге его работы исходная синтаксическая структура приближается к логической формуле при помощи трансформаций‑разверток до тех пор, пока формула не будет выражать смысл фразы. При этом, если исходная фраза неоднозначна, система в режиме диалога предлагает пользователю уточнить, какой из найденных машиной вариантов понимания он имел в виду.
Если подытожить сказанное, то суть проблемы заключается в том, что никакая, даже самая совершенная машина не может «понимать» текст на естественном языке так, как его понимает человек. Но она может однозначно воспринимать формулы математической логики. Поэтому задача формализации текста состоит в том, чтобы научиться устранять неопределенность и многозначность текстов на естественном языке при их переводе на формальный язык логики.
Разумеется, это один из многих путей, которым исследователи пытаются обучить компьютер пониманию естественного языка.
Дата добавления: 2014-11-13; просмотров: 544; Мы поможем в написании вашей работы!; Нарушение авторских прав |