КАТЕГОРИИ:
АстрономияБиологияГеографияДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРиторикаСоциологияСпортСтроительствоТехнологияФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Синтаксический анализ методом рекурсивного спуска.
Распознаватели с возвратом - это самый примитивный тип распознавателей для КС-языков. Логика их работы основана на моделировании недетерминированного МП-автомата.
Поскольку моделируется недетерминированный МП-автомат, то на некотором шаге работы моделирующего алгоритма существует возможность возникновения нескольких возможных следующих состояний автомата. В таком случае есть два варианта реализации алгоритма.
В первом варианте на каждом шаге работы алгоритм должен запоминать все возможные следующие состояния МП-автомата, выбирать одно из них, переходить в это состояние и действовать так до тех пор, пока либо не будет достигнуто конечное состояние автомата, либо автомат не перейдет в такую конфигурацию, когда следующее состояние будет не определено. Если достигнуто одно из конечных состояний — входная цепочка принята, работа алгоритма завершается. В противном случае алгоритм должен вернуть автомат на несколько шагов на зад, когда еще был возможен выбор одного из набора следующих состояний, выбрать другой вариант и промоделировать поведение автомата с этим условием. Алгоритм завершается с ошибкой, когда все возможные варианты работы автомата перебраны и при этом не было достигнуто ни одного из возможных конечных состояний.
Во втором варианте алгоритм моделирования МП-автомата должен на каждом шаге работы при возникновении неоднозначности с несколькими возможными следующими состояниями автомата запускать новую свою копию для обработки каждого из этих состояний. Алгоритм завершается, если хотя бы одна из выполняющихся его копий достигнет одного из конечных состояний. При этом работа всех остальных копий алгоритма прекращается. Если ни одна из копий алгоритма не достигла конечного состояния МП-автомата, то алгоритм завершается с ошибкой.
Второй вариант реализации алгоритма связан с управлением параллельными процессами в вычислительных системах, поэтому сложен в реализации. Кроме того, на каждом шаге работы МП-автомата альтернатив следующих состояний может быть много, а количество возможных параллельно выполняющихся процессов в операционных системах ограничено, поэтому применение второго варианта алгоритма осложнено. По этим причинам большее распространение получил первый вариант алгоритма, который предусматривает возврат к ранее запомненным состояниям МП-автомата, — отсюда и название «разбор с возвратами». Следует отметить, что, хотя МП-автомат является односторонним распознавателем, алгоритм моделирования его работы предусматривает возврат назад, к уже прочитанной части цепочки символов, чтобы исключить недетерминизм в поведении автомата (который невозможно промоделировать).
Есть еще одна особенность в моделировании МП-автомата: любой практически ценный алгоритм должен завершаться за конечное число шагов (успешно или неуспешно). Алгоритм моделирования работы произвольного МП-автомата в общем случае не удовлетворяет этому условию.
Чтобы избежать таких ситуаций, алгоритмы разбора с возвратами строят не для произвольных МП-автоматов, а для МП-автоматов, удовлетворяющих некоторым заданным условиям. Как правило, эти условия связаны с тем, что МП-автомат должен строиться на основе грамматики заданного языка только после того, Как она подвергнется некоторым преобразованиям. Поскольку преобразования грамматик сами по себе не накладывают каких-либо ограничений на входной класс КС-языков, то они и не ограничивают применимости алгоритмов разбора с возвратами — эти алгоритмы применимы для любого КС-языка, заданного произвольной КС-грамматикой.
Принцип работы нисходящего распознавателя с подбором альтернатив
Нисходящий распознаватель с подбором альтернатив моделирует работу МП-автомата с одним состоянием q:R({q},V,Z,δ,q,S,{q}). Автомат распознает цепочки КС-языка, заданного КС-грамматикой G(VT,VN,P,S). Входной алфавит автомата содержит терминальные символы грамматики: V = VT, а алфавит магазинных символов строится из терминальных и нетерминальных символов грамматики: Z = VT  VN.
VN.
Начальная конфигурация автомата определяется так: (q,α,S) — автомат пребывает в своем единственном состоянии q, считывающая головка находится в начале входной цепочки символов 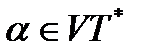 , в стеке лежит символ, соответствующий целевому символу грамматики S.
, в стеке лежит символ, соответствующий целевому символу грамматики S.
Конечная конфигурация автомата определяется так: (q,λ,λ) — автомат пребывает в своем единственном состоянии q, считывающая головка находится за концом входной цепочки символов, стек пуст.
Функция переходов МП-автомата строится на основе правил грамматики:
1. 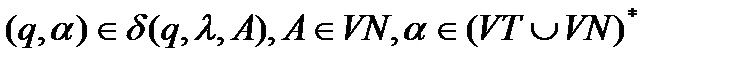 , если правило А → α содержится во
, если правило А → α содержится во
множестве правил Р грамматики G: А → α 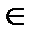 P;
P;
2. 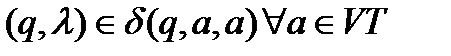 .
.
Работу данного МП-автомата можно неформально описать следующим образом: если на верхушке стека автомата находится нетерминальный символ А, то его молено заменить на цепочку символов а, если в грамматике языка есть правило А → α, не сдвигая при этом считывающую головку автомата (этот шаг работы называется «подбор альтернативы»); если же на верхушке стека находится терминальный символ а, который совпадает с текущим символом входной цепочки, то этот символ можно выбросить из стека и передвинуть считывающую головку на одну позицию вправо (этот шаг работы называется «выброс»). Данный МП-автомат может быть недетерминированным, поскольку при подборе альтернативы в грамматике языка может оказаться более одного правила вида А → α, тогда функция δ(q,λ,A) будет содержать более одного следующего состояния — у МП-автомата будет несколько альтернатив.
Решение о том, выполнять ли на каждом шаге работы МП-автомата выброс или подбор альтернативы, принимается однозначно. Моделирующий алгоритм должен обеспечивать выбор одной из возможных альтернатив и хранение информации о том, какие альтернативы на каком шаге уже были выбраны, чтобы иметь возможность вернуться к этому шагу и подобрать другие альтернативы. Такой алгоритм разбора называется алгоритмом с подбором альтернатив.
Данный МП-автомат строит левосторонние выводы для грамматики G(VT,VN,P,S). Для моделирования такого автомата необходимо, чтобы грамматика G(VT,VN,P,S) не была леворекурсивной, — в противном случае, очевидно, алгоритм может войти в бесконечный цикл. Поскольку, как было показано выше, произвольную КС-грамматику всегда можно преобразовать к нелеворекурсивному виду, этот алгоритм применим для любой КС-грамматики. Следовательно, им можно распознавать цепочки любого КС-языка.
Дата добавления: 2015-04-18; просмотров: 370; Мы поможем в написании вашей работы!; Нарушение авторских прав |