КАТЕГОРИИ:
АстрономияБиологияГеографияДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРиторикаСоциологияСпортСтроительствоТехнологияФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Математические функции для генерации случайных чисел
| Наименование функции | Формат функции | |
| Оригинальная версия | Локализованная версия | |
| RAND | СЛЧИС | СЛЧИС() - не имеет аргументов |
| RANDBETWEEN | СЛУЧМЕЖДУ | СЛУЧМЕЖДУ(нижн_граница; верхн_граница) |
Функция СЛЧИС()
Функция СЛЧИС() возвращает равномерно распределенное случайное число E, большее, либо равное 0 и меньшее 1, т.е.: 0  E < 1. Вместе с тем, путем несложных преобразований, с ее помощью можно получить любое случайное вещественное число. Например, чтобы получить случайное число между a и b, достаточно задать в любой ячейке ЭТ следующую формулу:
E < 1. Вместе с тем, путем несложных преобразований, с ее помощью можно получить любое случайное вещественное число. Например, чтобы получить случайное число между a и b, достаточно задать в любой ячейке ЭТ следующую формулу:
=СЛЧИС()*(b-a)+a
Эта функция не имеет аргументов. Если в ЭТ установлен режим автоматических вычислений, принятый по умолчанию, то возвращаемый функцией результат будет изменяться всякий раз, когда происходит ввод или корректировка данных. В режиме ручных вычислений пересчет всей ЭТ осуществляется только после нажатия клавиши [F9].
Настройка режима управления вычислениями производится установкой соответствующего флажка в подпункте "Вычисления" пункта "Параметры" темы "Сервис" главного меню.
В целом применение данной функции при решении задач финансового анализа ограничено рядом специфических приложений. Однако ее удобно использовать в некоторых случаях для генерации значений вероятности событий, а также вещественных чисел.
Функция СЛУЧМЕЖДУ(нижн_граница; верхн_граница)
Как следует из названия этой функции, она позволяет получить случайное число из заданного интервала. При этом тип возвращаемого числа (т.е. вещественное или целое) зависит от типа заданных аргументов.
В качестве примера, сгенерируем случайное значение для переменной Q (объем выпуска продукта). Согласно табл. 3.1, эта переменная принимает значения из диапазона 150 - 300.
Введите в любую ячейку ЭТ формулу:
=СЛУЧМЕЖДУ(150; 300) (Результат: 210)
(Читатель может получить другой результат - любое число из заданного диапазона)
Если задать аналогичные формулы для переменных P и V, а также формулу для вычисления NPV и скопировать их требуемое число раз, можно получить генеральную совокупность, содержащую различные значения исходных показателей и полученных результатов. После чего, используя рассмотренные в предыдущих главах статистические функции, нетрудно рассчитатьсоответствующие параметры распределения и провести вероятностный анализ.
Продемонстрируем изложенный подход на решении примера 3.1. Перед тем, как приступить к разработке шаблона, целесообразно установить в ЭТ режим ручных вычислений. Для этого необходимо выполнить следующие действия.
1. Выбрать в главном меню тему "Сервис".
2. Выбрать пункт "Параметры" подпункт "Вычисления".
3. Установить флажок "Вручную" и нажать кнопку "ОК".
Приступаем к разработке шаблона. С целью упрощения и повышения наглядности анализа выделим для его проведения в рабочей книге ППП EXCEL два листа.
 Первый лист - "Имитация", предназначен для построения генеральной совокупности (рис. 3.1). Определенные в данном листе формулы и собственные имена ячеек приведены в табл. 3.4. и 3.5.
Первый лист - "Имитация", предназначен для построения генеральной совокупности (рис. 3.1). Определенные в данном листе формулы и собственные имена ячеек приведены в табл. 3.4. и 3.5.
Рис. 3.1. Лист "Имитация"Таблица 3.4. Формулы листа "Имитация"
| Ячейка | Формула |
| Е7 | =B7+10-2 |
| A10 | =СЛУЧМЕЖДУ($B$3;$C$3) |
| A11 | =СЛУЧМЕЖДУ($B$3;$C$3) |
| B10 | =СЛУЧМЕЖДУ($B$4;$C$4) |
| B11 | =СЛУЧМЕЖДУ($B$4;$C$4) |
| C10 | =СЛУЧМЕЖДУ($B$5;$C$5) |
| C11 | =СЛУЧМЕЖДУ($B$5;$C$5) |
| D10 | =(B10*(C10-A10)-Пост_расх-Аморт)*(1-Налог)+Аморт |
| D11 | =(B11*(C11-A11)-Пост_расх-Аморт)*(1-Налог)+Аморт |
| E10 | =ПЗ(Норма;Срок;-D10)-Нач_инвест |
| E11 | =ПЗ(Норма;Срок;-D11)-Нач_инвест |
| Адрес ячейки | Имя | Комментарии |
| Блок A10:A11 | Перем_расх | Переменные расходы |
| Блок B10:B11 | Количество | Объем выпуска |
| Блок C10:C11 | Цена | Цена изделия |
| Блок D10:D11 | Поступления | Поступления от проекта NCFt |
| Блок E10:E11 | ЧСС | Чистая современная стоимость NPV |
Таблица 3.5.
Имена ячеек листа "Имитация"
Первая часть листа (блок ячеек А1.Е7) предназначена для ввода диапазонов изменений ключевых переменных, значения которых будут генерироваться в процессе проведения эксперимента. В ячейке В7 задается общее число имитаций (экспериментов). Формула, заданная в ячейке Е7, вычисляет номер последней строки выходного блока, в который будут помещены полученные значения. Смысл этой формулы будет раскрыт позже.
Вторая часть листа (блок ячеек А9.Е11) предназначена для проведения имитации. Формулы в ячейках А10.С11 генерируют значения для соответствующих переменных с учетом заданных в ячейках В3.С5 диапазонов их изменений. Обратите внимание на то, что при указании нижней и верхней границы изменений используется абсолютная адресация ячеек.
Формулы в ячейках D10.E11вычисляют величину потока платежей и его чистую современную стоимость соответственно. При этом значения постоянных переменных берутся из следующего листа шаблона - "Результаты анализа".
Лист "Результаты анализа" кроме значений постоянных переменных содержит также функции, вычисляющие параметры распределения изменяемых (Q, V, P) и результатных (NCF, NPV) переменных и вероятности различных событий. Определенные для данного листа формулы и собственные имена ячеек приведены в табл. 3.6 и 3.7. Общий вид листа показан на рис. 3.2.
Таблица 3.3.
Формулы листа "Результаты анализа"
| Ячейка | Формула |
| B8 | =СРЗНАЧ(Перем_расх) |
| B9 | =СТАНДОТКЛОНП(Перем_расх) |
| B10 | =B9/B8 |
| B11 | =МИН(Перем_расх) |
| B12 | =МАКС(Перем_расх) |
| C8 | =СРЗНАЧ(Количество) |
| C9 | =СТАНДОТКЛОНП(Количество) |
| C10 | =C9/C8 |
| C11 | =МИН(Количество) |
| C12 | =МАКС(Количество) |
| D8 | =СРЗНАЧ(Цена) |
| D9 | =СТАНДОТКЛОНП(Цена) |
| D10 | =D9/D8 |
| D11 | =МИН(Цена) |
| D12 | =МАКС(Цена) |
| E8 | =СРЗНАЧ(Поступления) |
| E9 | =СТАНДОТКЛОНП(Поступления) |
| E10 | =E9/E8 |
| E11 | =МИН(Поступления) |
| E12 | =МАКС(Поступления) |
| F8 | =СРЗНАЧ(ЧСС) |
| F9 | =СТАНДОТКЛОНП(ЧСС) |
| F10 | =F9/F8 |
| F11 | =МИН(ЧСС) |
| F12 | =МАКС(ЧСС) |
| F13 | =СЧЁТЕСЛИ(ЧСС;"<0") |
| F14 | =СУММЕСЛИ(ЧСС;"<0") |
| F15 | =СУММЕСЛИ(ЧСС;">0") |
| Е18 | =НОРМАЛИЗАЦИЯ(D18;$F$8;$F$9) |
| F18 | =НОРМСТРАСП(E18) |
Таблица 3.7.
Имена ячеек листа "Результаты анализа"
| Адрес ячейки | Имя | Комментарии |
| B2 | Нач_инвест | Начальные инвестиции |
| B3 | Пост_расх | Постоянные расходы |
| B4 | Аморт | Амортизация |
| D2 | Норма | Норма дисконта |
| D3 | Налог | Ставка налога на прибыль |
| D4 | Срок | Срок реализации прока |
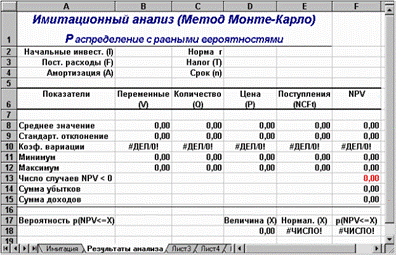
Рис. 3.2. Лист "Результаты анализа"
Поскольку формулы листа содержат ряд новых функций, приведем необходимые пояснения.
Функции МИН() и МАКС() вычисляют минимальное и максимальное значение для массива данных из блока ячеек, указанного в качестве их аргумента.Имена и диапазоны этих блоков приведены в табл. 3.7.
Функция СЧЕТЕСЛИ() осуществляет подсчет количества ячеек в указанном блоке, значения которых удовлетворяют заданному условию. Функция имеет следующий формат:
=СЧЕТЕСЛИ(блок; "условие").
В данном случае, заданная в ячейке F13, эта функция осуществляет подсчет количества отрицательных значений NPV, содержащихся в блоке ячеек ЧСС (см. табл. 3.7).
Механизм действия функции СУММЕСЛИ() аналогичен функции СЧЕТЕСЛИ().Отличие заключается лишь в том,что эта функция суммирует значения ячеек в указанном блоке, если они удовлетворяют заданному условию. Функция имеет следующий формат:
=СУММЕСЛИ(блок; "условие").
В данном случае, заданные в ячейках F14.F15, функции осуществляет подсчет суммы отрицательных (ячейка F14) и положительных (ячейка F14) значений NPV,содержащихся в блоке ЧСС. Смысл этих расчетов будет объяснен позже.
Две последние формулы (ячейки Е18и F18) предназначены для проведения вероятностного анализа распределения NPV и требуют небольшого теоретического отступления.
В рассматриваемом примере мы исходим из предположения о независимости и равномерном распределении ключевых переменных Q, V, P. Однако какое распределение при этом будет иметь результатная величина - показатель NPV, заранее определить нельзя.
Одно из возможных решений этой проблемы - попытаться аппроксимировать неизвестное распределение каким-либо известным. При этом в качестве приближения удобнее всего использовать нормальное распределение. Это связано с тем, что в соответствии с центральной предельной теоремой теории вероятностей при выполнении определенных условий сумма большого числа случайных величин имеет распределение, приблизительно соответствующее нормальному.
В прикладном анализе для целей аппроксимации широко применяется частный случай нормального распределения - т.н.стандартное нормальное распределение. Математическое ожидание стандартно распределенной случайной величины Е равно 0: M(E) = 0. График этого распределения симметричен относительно оси ординат и оно характеризуется всего одним параметром - стандартным отклонением 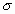 , равным 1.
, равным 1.
Приведение случайной переменной E к стандартно распределенной величине Z осуществляется с помощью т.н. нормализации - вычитания средней и последующего деления на стандартное отклонение:
 (3.3).
(3.3).
Как следует из (3.3), величина Z выражается в количестве стандартных отклонений. Для вычисления вероятностей по значению нормализованной величины Z используются специальные статистические таблицы.
В ППП EXCEL подобные вычисления осуществляются с помощью статистических функций НОРМАЛИЗАЦИЯ() и НОРМСТРАСП().
Функция НОРМАЛИЗАЦИЯ(x; среднее; станд_откл)
Эта функция возвращает нормализованное значение Z величины x, на основании которого затем вычисляется искомая вероятность p(E 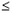 x). Она реализует соотношение (3.3). Функция требует задания трех аргументов:
x). Она реализует соотношение (3.3). Функция требует задания трех аргументов:
х - нормализуемое значение;
среднее - математическое ожидание случайной величины Е;
станд_откл - стандартное отклонение.
Полученное значение Z является аргументом для следующей функции - НОРМСТРАСП().
Функция НОРМСТРАСП(Z)
Эта функция возвращает стандартное нормальное распределение, т.е. вероятность того, что случайная нормализованная величина Е будет меньше или равна х. Она имеет всего один аргумент - Z, вычисляемый функцией НОРМАЛИЗАЦИЯ().
Нетрудно заметить,что эти функции следует использовать в тандеме. При этом наиболее эффективным и компактным способом их задания является указаниефункции НОРМАЛИЗАЦИЯ() в качестве аргумента функции - НОРМСТРАСП(), т.е.:
=НОРМСТРАСП(НОРМАЛИЗАЦИЯ(x; среднее; станд_откл)).
С целью повышения наглядности, в проектируемом шаблоне функции заданы раздельно (ячейки Е18 и F18).
Сформируйте данный шаблон и сохраните его на магнитном диске под именем SIMUL_1.XLT. Приступаем к имитационному эксперименту. Для его проведения необходимо выполнить следующие шаги.
1. Ввести значения постоянных переменных (табл. 3.2) в ячейки В2.В4 и D2.D4 листа "Результаты анализа".
2. Ввести значения диапазонов изменений ключевых переменных (табл. 3.1) в ячейки В3.С5 листа "Имитация".
3. Задать в ячейке В7 требуемое число экспериментов.
4. Установить курсор в ячейку А11 и вставить необходимое число строк в шаблон (номер последней строки будет вычислен в Е7).
5. Скопировать формулы блока А10.Е10 требуемое количество раз.
6. Перейти к листу "Результаты анализа" и проанализировать полученные результаты.
Рассмотрим реализацию выделенных шагов более подробно. Выполнение первых трех пунктов не должно вызвать особых затруднений. Введите значения постоянных переменных в ячейки В2.В4 листа "Результаты анализа". Введите значения диапазонов изменений ключевых переменных в ячейки В3.С5 листа "Имитация". Укажите в ячейке В7 число проводимых экспериментов, например - 500. Установите табличный курсор в ячейку А11.
На следующем шаге необходимо вставить в шаблон нужное количество строк (498) (Поскольку первая и последняя строка блока уже определены, число вставляемых строк равно: 500 - 2 = 498). Однако выделение такого количества строк при помощи указателя мыши - достаточно трудоемкая операция. К счастью ППП EXCEL предоставляет более эффективные процедуры для выполнения подобных операций. В частности, в данном случае можно воспользоваться операцией перехода, которую также удобно применять и для выделения больших диапазонов ячеек.
Нажмите функциональную клавишу [F5]. На экране появится окно диалога "Переход" (рис. 3.3).
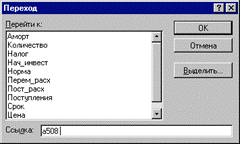
Рис. 3.3. Окно диалога "Переход"
Для перехода к нужному участку электронной таблицы достаточно указать в поле "Ссылка" адрес или имя соответствующей ячейки (блока). В данном случае, таким адресом будет любая ячейка последней вставляемой строки, номер которой вычислен в ячейке Е7 (508). Например, в качестве адреса перехода может быть указана ячейка А508.
Введите в поле "Ссылка" адрес: А508 и нажмите комбинацию клавиш [SHIFT] + [ENTER]. Результатом выполнения этих действий будет выделение блока А11.А508. После чего осуществите вставку строк любым из известных вам способов.
Теперь необходимо заполнить вставленные строки формулами блока ячеек А10.Е10. Для этого выполните следующие действия.
1. Выделите и скопируйте в буфер блок ячеек А10.Е10.
2.  Нажмите комбинацию клавиш [CTRL] + [SHIFT] + [
Нажмите комбинацию клавиш [CTRL] + [SHIFT] + [  ].
].
3. Нажмите клавишу [ENTER].
4. Нажмите клавишу [F9] (Этот пункт выполняется в том случае, если был установлен режим ручного пересчета).
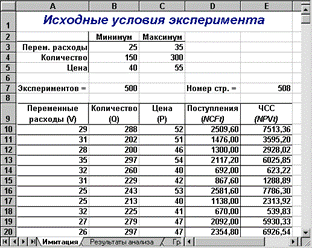
Результатом выполнения этих действий будет заполнение блока А10.Е509случайными значениями ключевых переменных V, Q, P и результатами вычислений величин NCF и NPV. Фрагмент результатов имитации, полученных автором, приведен на рис. 3.4 (Необходимо все время помнить о случайной природе эксперимента. Полученные вами результаты будут отличаться от приведенных). Соответствующие проведенному эксперименту результаты анализа приведены на рис. 3.5.
Рис. 3.4. Результаты имитации
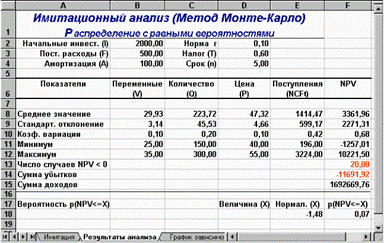
Рис. 3.5. Результаты анализа
Нетрудно заметить, что по результатам имитационного анализа риск проекта значительно ниже. Величина ожидаемой NPV меньше результата предыдущего анализа (3361,96 и 4502,30 соответственно). Однако величина стандартного отклонения также существенно ниже (2271,31 и 4673,62) и не превышает значения NPV. Коэффициент вариации (0,68) меньше 1, таким образом риск данного проекта в целом ниже среднего риска инвестиционного портфеля фирмы. Результаты вероятностного анализа показывают, что шанс получить отрицательную величину NPV не превышает 7%. Еще больший оптимизм внушают результаты анализа распределения чистых поступлений от проекта NCF. Величина стандартного отклонения здесь составляет всего 42% от среднего значения. Таким образом с вероятностью более 90% можно утверждать, что поступления от проекта будут положительными величинами.
Сумма всех отрицательных значений NPV в полученной генеральной совокупности (ячейка F14) может быть интерпретирована как чистая стоимость неопределенности для инвестора в случае принятия проекта. Аналогично сумма всех положительных значений NPV (ячейка F15) может трактоваться как чистая стоимость неопределенности для инвестора в случае отклонения проекта. Несмотря на всю условность этих показателей, в целом они представляют собой индикаторы целесообразности проведения дальнейшего анализа.
В данном случае они наглядно демонстрируют несоизмеримость суммы возможных убытков по отношению к общей сумме доходов (-11691,92 и 1692669,76 соответственно).
На практике одним из важнейших этапов анализа результатов имитационного эксперимента является исследование зависимостей между ключевыми параметрами. Как было показано в предыдущей главе, количественная оценка вариации напрямую зависит от степени корреляции между случайными величинами. Методы оценки степени зависимости, а также технология ее автоматизации путем применения специальных инструментов ППП EXCEL, будут продемонстрированы ниже. Здесь же мы ограничимся визуальным (графическим) исследованием. На рис. 3.6 приведен график распределения значений ключевых параметров V, P и Q, построенный на основании 75 имитаций.
Нетрудно заметить, что в целом, вариация значений всех трех параметров носит случайный характер, что подтверждает принятую ранее гипотезу о их независимости. Для сравнения ниже приведен график распределений потока платежей NCF и величины NPV (рис. 3.7).

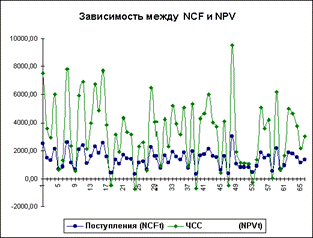
Рис. 3.6 Распределение значений параметров V, P и Q
Рис. 3.7. Зависимость между NCF и NPV
Как и следовало ожидать, направления колебаний здесь в точности совпадают и между этими величинами существует сильная корреляционная связь, близкая к функциональной. Дальнейшие расчеты показали, что величина коэффициента корреляции между полученными распределениями NCF и NPV оказалась равной 1.
Подводя итоги отметим, что в целом применение рассмотренной технологии проведения имитационных экспериментов в среде EXCEL - достаточно трудоемкий процесс, который к тому же ограничивается случаем равномерного распределения исследуемых переменных.
Гораздо более удобным и эффективным способом решения таких задач в среде ППП EXCEL является использование специального инструмента анализа - "Генератор случайных чисел".
3.2.2. Имитация с инструментом "Генератор случайных чисел"
Этот инструмент предназначен для автоматической генерации множества данных (генеральной совокупности) заданного объема, элементы которого характеризуются определенным распределением вероятностей. При этом могут быть использованы 7 типов распределений: равномерное, нормальное, Бернулли, Пуассона, биномиальное, модельное и дискретное. Применение инструмента "Генератор случайных чисел", как и большинства используемых в этой работе функций, требует установки специального дополнения "Пакет анализа".
Для демонстрации техники применения этого инструмента изменим условия примера 3.1, определив вероятности для каждого сценария развития событий следующим образом (табл. 3.8). Мы также будем исходить из предположенияо нормальном распределенииключевых переменных. Количество имитаций оставим прежним - 500.
Таблица 3.8.
Вероятностные сценарии реализации проекта
| Показатели | Сценарий | ||
| Наихудший P = 0.25 | Наилучший P = 0.25 | Вероятный P = 0.5 | |
| Объем выпуска - Q | |||
| Цена за штуку - P | |||
| Переменные затраты - V |
Приступим к формированию шаблона. Как и в предыдущем случае, выделим в рабочей книге два листа: "Имитация" и "Результаты анализа".
Формирование шаблона целесообразно начать с листа "Результаты анализа" (рис. 3.8.).
Рис. 3.8. Лист "Результаты анализа" (шаблон II)
Как следует из рис. 3.8 этот лист практически соответствует ранее разработанному для решения предыдущей задачи (см. рис. 3.2). Отличие составляют лишь формулы для расчета вероятностей, которые приведены в табл. 3.9.
Таблица 3.9.
 Формулы листа "Результаты анализа" (шаблон II)
Формулы листа "Результаты анализа" (шаблон II)
| Ячейка | Формула |
| В17 | =НОРМРАСП(0;B8;B9;1) |
| В18 | =НОРМРАСП(B11;B8;B9;1) |
| В19 | =НОРМРАСП(B12;B8;B9;1)-НОРМРАСП(B8+B9;B8;B9;1) |
| В20 | =НОРМРАСП(B8;B8;B9;1)-НОРМРАСП(B8-B9;B8;B9;1) |
| С17 | =НОРМРАСП(0;C8;C9;1) |
| С18 | =НОРМРАСП(C11;C8;C9;1) |
| С19 | =НОРМРАСП(C12;C8;C9;1)-НОРМРАСП(C8+C9;C8;C9;1) |
| С20 | =НОРМРАСП(C8;C8;C9;1)-НОРМРАСП(C8-C9;C8;C9;1) |
| D17 | =НОРМРАСП(0;D8;D9;1) |
| D18 | =НОРМРАСП(D11;D8;D9;1) |
| D19 | =НОРМРАСП(D12;D8;D9;1)-НОРМРАСП(D8+D9;D8;D9;1) |
| D20 | =НОРМРАСП(D8;D8;D9;1)-НОРМРАСП(D8-D9;D8;D9;1) |
| E17 | =НОРМРАСП(0;E8;E9;1) |
| E18 | =НОРМРАСП(E11;E8;E9;1) |
| E19 | =НОРМРАСП(E12;E8;E9;1)-НОРМРАСП(E8+E9;E8;E9;1) |
| E20 | =НОРМРАСП(E8;E8;E9;1)-НОРМРАСП(E8-E9;E8;E9;1) |
| F17 | =НОРМРАСП(0;F8;F9;1) |
| F18 | =НОРМРАСП(F11;F8;F9;1) |
| F19 | =НОРМРАСП(F12;F8;F9;1)-НОРМРАСП(F8+F9;F8;F9;1) |
| F20 | =НОРМРАСП(F8;F8;F9;1)-НОРМРАСП(F8-F9;F8;F9;1) |
Используемые в нем собственные имена ячеек также взяты из аналогичного листа предыдущего шаблона (см. табл. 3.7).
Для быстрого формирования нового листа "Результаты анализа" выполните следующие действия.
1. Загрузите предыдущий шаблон SIMUL_1.XLT и сохраните его под другим именем, например - SIMUL_2.XLT
2. Удалите лист "Имитация". Для этого установите указатель мыши на ярлычок этого листа и нажмите правую кнопку. Результатом выполнения этих действий будет появления списка операций в виде контекстного меню. Выберите операцию "Удалить". Подтвердите свое решение нажатием кнопки "ОК" в появившемся диалоговом окне.
3. Перейдите в лист "Результаты анализа". Удалите строки 17-18. Откорректируйте заголовок ЭТ.
4. Добавьте формулы из табл. 3.9. Для этого введите соответствующие формулы в ячейки блока В17.В20и скопируйте их в блок С17.F20. Введите соответствующие комментарии.
5. Сверьте полученную таблицу с рис. 3.8.
Перейдите к следующему листу и присвойте ему имя - "Имитация". Приступаем к его формированию (рис. 3.9).
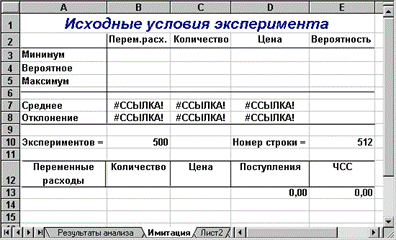
Рис. 3.9. Лист "Имитация" (шаблон II)
Первая часть этого листа (блок ячеек А1.Е10) предназначена для ввода исходных данных и расчета необходимых параметров их распределений. Напомним, что нормальное распределение случайной величины характеризуется двумя параметрами - математическим ожиданием (средним) и стандартным отклонением. Формулы расчета указанных параметров для ключевых переменных модели заданы в блоках ячеек В7.D7иB8.D8 соответственно (см. табл. 3.11). Для удобства определения формул и повышения их наглядности блоку ячеек Е3.Е5присвоено имя"Вероятности" (см. табл. 3.10).
Таблица 3.10.
Имена ячеек листа "Имитация" (шаблон II)
| Адрес ячейки | Имя | Комментарии |
| Блок Е3:Е5 | Вероятности | Вероятность значения параметра |
| Блок A13:A512 | Перем_расх | Переменные расходы |
| Блок B13:B512 | Количество | Объем выпуска |
| Блок C13:C512 | Цена | Цена изделия |
| Блок D13:D512 | Поступления | Поступления от проекта NCF |
| Блок E13:E512 | ЧСС | Чистая современная стоимость NPV |
Таблица 3.11.
Формулы листа "Имитация" (шаблон II)
| Ячейка | Формула |
| В7 | =СУММПРОИЗВ(B3:B5; Вероятности) |
| В8 | {=КОРЕНЬ(СУММПРОИЗВ((B3:B5 - B7)^2; Вероятности))} |
| С7 | =СУММПРОИЗВ(C3:C5; Вероятности) |
| С8 | {=КОРЕНЬ(СУММПРОИЗВ((C3:C5 - C7)^2; Вероятности))} |
| D7 | =СУММПРОИЗВ(D3:D5; Вероятности) |
| D8 | {=КОРЕНЬ(СУММПРОИЗВ((D3:D5 - D7)^2; Вероятности))} |
| E10 | =B10+13 -1 |
| D13 | =(B13*(C13-A13)-Пост_расх-Аморт)*(1-Налог)+Аморт |
| E13 | =ПЗ(Норма; Срок; -D13) - Нач_инвест |
Обратите внимание на то, что для расчета стандартных отклонений используются формулы-массивы, правила задания которых были рассмотрены в предыдущей главе. Для формирования блока формул достаточно определить их для ячеек В7.В8 и затем скопировать в блок С7.D8.
Формула в ячейке Е10 по заданному числу имитаций (ячейка В10) вычисляет номер последней строки для блоков, в которых будут храниться сгенерированные значения ключевых переменных.
Ячейки D13.E13 содержат уже знакомые нам формулы для расчета величины потока платежей NCF и его чистой современной стоимости NPV.
Сформируйте элементы оформления листа "Имитация", определите необходимые имена для блоков ячеек (табл. 3.10) и задайте требуемые формулы (табл. 3.11). Сверьте полученную ЭТ с рис. 3.9. Сохраните полученный шаблон под именем SIMUL_2.XLT.
Введите исходные значения постоянных переменных (табл. 3.2) в ячейки В2.В4иD2.D4листа "Результаты анализа". Перейдите к листу "Имитация". Введите значения ключевых переменных и соответствующие вероятности (табл. 3.8). Полученная в результате ЭТ должна иметь вид рис. 3.10.

Рис. 3.10. Лист "Имитация" после ввода исходных данных
Установите курсор в ячейку А13. Приступаем к проведению имитационного эксперимента.
1. Выберите в главном меню тему "Сервис" пункт "Анализ данных". Результатом выполнения этих действий будет появление диалогового окна "Анализ данных", содержащего список инструментов анализа.
2. Выберите из списка "Инструменты анализа" пункт "Генерация случайных чисел" и нажмите кнопку "ОК" (рис. 3.11).
3.  На экране появится диалоговое окно "Генерация случайных чисел". Укажите в списке "Распределения" требуемый тип - "Нормальное". Заполните остальные поля изменившегося окна согласно рис. 3.12 и нажмите кнопку "ОК". Результатом будет заполнение блока ячеек А13.А512(переменные расходы)сгенерированными случайными значениями.
На экране появится диалоговое окно "Генерация случайных чисел". Укажите в списке "Распределения" требуемый тип - "Нормальное". Заполните остальные поля изменившегося окна согласно рис. 3.12 и нажмите кнопку "ОК". Результатом будет заполнение блока ячеек А13.А512(переменные расходы)сгенерированными случайными значениями.

Рис. 3.11. Выбор инструмента "Генерация случайных чисел"
Рис. 3.12. Заполнение полей окна "Генерация случайных чисел"
Приведем необходимые пояснения. Первым заполняемым аргументом диалогового окна "Генерация случайных чисел" является поле "Число переменных". Оно задает количество колонок ЭТ, в которых будут размещаться сгенерированные в соответствии с заданным законом распределения случайные величины. В нашем примере оно должно содержать 1, так как ранее мы отвели под значения переменной V (переменные расходы) в ЭТ одну колонку - "А". В случае, если указывается число больше 1, случайные величины будут размещены в соответствующем количестве соседних колонок, начиная с активной ячейки. Если это число не введено, то все колонки в выходном диапазоне будут заполнены.
Следующим обязательным аргументом для заполнения является содержимое поля "Число случайных чисел" (т.е. - количество имитаций). Согласно условиям примера оно должно быть равно 500 (см. рис. 3.12). При этом ППП EXCEL автоматически подсчитывает необходимое количество ячеек для хранения генеральной совокупности.
Необходимый вид распределения задается путем соответствующего выбора из списка "Распределения". Как уже отмечалось ранее, могут быть получены 7 наиболее распространенных в практическом анализе типов распределений, каждое из которых характеризуется собственными параметрами. Выбранный тип распределения определяет внешний вид диалогового окна. В рассматриваемом примере выбор типа распределения "Нормальное" повлек за собой появление дополнительных аргументов - его параметров "Среднее" и "Стандартное отклонение", рассчитанных ранее для исследуемой переменной V в ячейках В7и В8 листа "Имитация". К сожалению эти аргументы могут быть заданы только в виде констант. Использование адресов ячеек и собственных имен здесь не допускается!
Указание аргумента "Случайное рассеивание" позволяет при повторных запусках генератора получать те же значения случайных величин, что и при первом. Таким образом одну и ту же генеральную совокупность случайных чисел можно получить несколько раз, что значительно повышает эффективность анализа (сравните с предыдущим шаблоном!). В случае если этот аргумент не задан (равен 0), при каждом последующем запуске генератора будет формироваться новая генеральная совокупность. В нашем примере этот аргумент задан равным 1, что позволит нам оперировать с одной и той же генеральной совокупностью и избежать постоянных перерасчетов ЭТ.
Последний аргумент диалогового окна "Генерация случайных чисел" - "Параметры вывода" определяет место расположения полученных результатов. Место вывода задается путем установления соответствующего флажка. При этом можно выбрать три варианта размещения:
· выходной блок ячеек на текущем листе - введите ссылку на левую верхнюю ячейку выходного диапазона, при этом его размер будет определен автоматически и в случае возможного наложения генерируемых значений на уже имеющиеся данные на экран будет выведено предупреждающее сообщение;
· новый рабочий лист - в рабочей книге будет открыт новый лист, содержащий результаты генерации случайных величин, начиная с ячейки A1;
· новая рабочая книга - будет открыта новая книга с результатами имитации на первом листе.
В рассматриваемом примере для проведения дальнейшего анализа необходимо, чтобы случайные величины размещались в специально отведенные для них блоки ячеек (см. табл. 3.10). В частности для хранения 500 значений первой переменной ранее был отведен блок ячеек А13.А512. Поскольку для этого блока определено собственной имя - "Перем_расх", оно указано в качестве выходного диапазона. Отметим, что при увеличении либо уменьшении количества имитаций необходимо также переопределить и выходные блоки, предназначенные для хранения значений переменных.
Генерация значений остальных переменных Q и Р осуществляется аналогичным образом, путем выполнения шагов 1-3. Пример заполнения окна "Генерация случайных чисел" для переменной Q (количество) приведен на рис. 3.13.

Рис. 3.13. Заполнение полей окна для переменной Q
Для получения генеральной совокупности значений потока платежей и их чистой современной стоимости необходимо скопировать формулы базовой строки (ячейки D13.E13) требуемое число раз (499). С проблемой копирования больших диапазонов ячеек мы уже сталкивались в предыдущем примере.
Ее решение осуществляется выполнением следующих действий.
1. Выделите и скопируйте в буфер ячейку D13.
2. Нажмите клавишу [F5]. На экране появится диалоговое окно "Переход".
3. Укажите в поле "Ссылка" имя блока "Поступления" и нажмите кнопку "ОК". Результатом этих действий будет выделение заданного блока.
4. Нажмите клавишу[ENTER].
5. В случае, если в ЭТ был установлен режим ручных вычислений, нажмите клавишу [F9].
Аналогичным образом копируется формула из ячейки Е13. При этом в поле "Ссылка" диалогового окна "Переход" необходимо указать имя блока - "ЧСС". Вы также можете выбрать необходимое имя из списка "Перейти к".
Полученные автором результаты решения примера приведены на рис. 3.14 - 3.15.
Результаты проведенного имитационного эксперимента ненамного отличаются от предыдущих. Величина ожидаемой NPV равна 3412,14 при стандартном отклонении 2556,83. Коэффициент вариации (0,75) несколько выше, но меньше 1, таким образом риск данного проекта в целом ниже среднего риска инвестиционного портфеля фирмы. Результаты вероятностного анализа показывают, что шанс получить отрицательную величину NPV не превышает 9%. Общее число отрицательных значений NPV в выборке составляет 32 из 500. Таким образом с вероятностью около 91% можно утверждать, что чистая современная стоимость проекта будет больше 0. При этом вероятность того, что величина NPV окажется больше чем М(NPV) + , равна 16% (ячейка F19). Вероятность попадания значения NPV в интервал [М(NPV) - ; М(NPV)] равна 34%.

Рис. 3.14. Результаты имитационного эксперимента (шаблон II)
Рис. 3.15. Результаты анализа (шаблон II)
Дата добавления: 2015-01-19; просмотров: 340; Мы поможем в написании вашей работы!; Нарушение авторских прав |