КАТЕГОРИИ:
АстрономияБиологияГеографияДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРиторикаСоциологияСпортСтроительствоТехнологияФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Включения записи в БД
- Запись сохраняется в таблице БД
- Выполняется с помощью хэш-функции, номер раздела по ключу
h(q)=i – номер хэш индекса
И в этот раздел (i) помещается запись (q,P), где это указатель на индекс БД.
q→h(q)=i→
Чтение i-ого раздела хэш-индекса→
Поиск записи (q, P) в i-ом разделе по ключу q→
Чтение блока из таблицы БД по указателю P→
Поиск в блоке требуемой записи.
Для того, чтобы прочитать требуемое №2 обращение к диску.
B – индексы.
Сторятся для следующих атрибутов:
- Для первичного ключа. (Primary Key)
- Для альтернативного ключа. (AK – другой уникальный ключ)
- Для произвольного набора атрибутов. (IK – инвертированные списки)
Для первых двух случаев, значение ключей в индексе не могут повторяться (всегда уникален)
В 3 случае, значение индексируемых атрибутов могут повторяться в индексе (Фамилия)
Какие существуют
Различают следующие типы B- индексов.
- Обычные B-индексы (B-деревья)
- Битовые индексы (Bit Mappend)
- Реверсивыне индексы (Reverse Key Index)
- Индекс Таблицы (Индекс Таблицы)
Структура
Обычный индекс представляет собой совокупность иерархически-связанных блоков, а када запись блока листового уровня имеет следующую структуру:
<Значение индекс. Атрибута (mean) идентификатор записи табл. БД (rowid)>

При переполнении таблицы делятся пополам – B – деревья.
Если нужно ‘B’ →
- читаю ‘A’ – 1 уровень. ≠Г
- читаю, например, ‘Г’ дальше в 1 уровне ≠B и лексикографически это больше, чем ‘B’→
- Возврящаюсь назад к ‘А’ и иду на 2 уровень
- Читаю на II уровне ‘A’ ≠’B’
- ‘B’=’B’ → конец.
(q, rowid)
/
Значение инд. Атрибута
Все записи блоков любого уровня упорядочены по значению главного атрибута. Если места в блоке листового уровня, то запись выполняетс в этот блок.
Если мест нет, то блок листового уровня расширяется на 2.
Ниняя часть старого блока переписывается в нижнюю часть нового блока и в блоке более верхнего уровня создается mean – указатель.
Предположим необходимо найти записи со значением индексного атрибута = q.
Раз просматриватся индекс, начиная с 1 уровня и на каждом уровне q<= mean из указателя читается информация следующего уровня, просматривается и т. д.
Когда будет считан блок листового уровня q=mean.
После этого определяется rowid и по этим идентификаторам выполняется чтение или запись.
ROWID
00001<3aA идентификатор файла БД.
0007 – номер блока.
0002 – номер записи.
Данный пример указывает, что 0002, 0003 имеет значение индекс атрибута с А.
Определение числа уровней в обычном
Число уровней является переменным и определяется из того, что число блоков в индексе на 1 уровне всегда =1.
- V – число записей в таблице БД.
- К – маx число записей в 1-одном блоке индекса
- L- число уровней в индексе
Все переполнены уровни, сколько уровней?
V/K – количество блоков листового уровня.
V/K  - число блоков индекса на L-1 уровне.
- число блоков индекса на L-1 уровне.
.
.
V/K =1 – число блоков в индексе на 1 уровне.
L = log  V
V
Преимущества и недостатки обычных B – деревьев
Преимущества:
- При обновлении записи в таблице БД, блокируется только эта запись.
- Очень хорошо изучены
- Эффективные алгоритмы их реализации
Недостатки:
- Достаточно большой объем внешней памяти, занимаемой индексом
Рассчитаем объем, занимаемый листовыми блоками обычного B-индекса.
- V – число записей в таблице БД.
- I – мощность индекс. атрибута (число различных значений)
- L
 - длина индекс. атриб. В схеме таблицы
- длина индекс. атриб. В схеме таблицы - L
 - длина идентификатора записи (rowid)
- длина идентификатора записи (rowid)
Предположим, что все блоки листового уровня заполнены.
Тогда объем этих блоков Q=V(L + L )
Лекция 13
Недостатки обычных В-деревьев:
- большое время выполнения операций над списками с индексированными записями
Пример
Пусть условие поиска в БД имеет следующий вид:
q = ‘A’ AND s = ‘B’
| q | s | |||
| A | B |  
| ||
Индексы строятся для атрибутов какой-либо 1 таблицы. Предположим, что атрибуты q и s индексированы. Поиск требуемых записей в индексе осуществляется следующим образом:
1) используя индекс для q система идентификаторы записей, у которых q=’A’.
q=’A’ –
2) используя индекс для s система идентификаторы записей, у которых s=’B’.
s=’b’ – {rowid}s=’B’
3) для получения результирующего списка результатов система строит пересечение списков
{rowid}q=’A’  {rowid}s=’B’
{rowid}s=’B’
4) Используя полученные идентификаторы записи читаются из БД
При выполнении 3 пункта СУБД организует вложенные циклы для просмотра и определения пересечений списков. На это тратится достаточно много времени.
Примечание.
Иногда чтобы улучшить время выполнения запроса поиск записей осуществляется по 1 индексированному атрибуту, остальные условия проверяются программно.
------------------------------------------------------------------------------------------------------------------------
БИЛЕТ 4
1. Способы описания диаграммы "сущность-связь" при проектировании концептуальной схемы базы данных. Пример.
Проектирование инфологической схемы БД.
Для описания схем БД используется диаграмма «сущность- связь» (ERD Entity – relationship diagram)
Для разработки ERD используется следующая нотация:
1. Нотация Чена (используется для ручного проектирования информационных схем)
2. Нотация Барнера (используется для машинного проектирования схем БД Oracle)
3. Нотация IDE F1x (ERwin, PowerDesigner) ERwin позволят создавать инфологические схемы, а потом автоматически генерировать даталогические модели для более чем 20 СУБД.
|
– независимая сущность. Эта сущность может присутствовать в схеме БД в 2х случаях:
-сущность не является дочерней
-она является дочерней, но связанна с родительской сущностью, не идентифицирующей связью.

– зависимая сущность. Может присутствовать в схеме БД, только если эта сущность является дочерней и связанна с родительской сущностью идентифицирующей связью.

- обозначает связь между сущностями.
Характеристики связей приведены в следующей таблице.
| Тип связи | ||
| Свойства | Идентифицирующая | Неидентифицирующая |
| Обозначения на диаграмме Гена | Глагольная форма со знаком * | Глагольная форма без знака * |
| Куда добавляются ключ родительской сущности при создании дочерней 1:М (1 – родительская; М - дочерняя) | К ключевым атрибутам дочерней сущности | К не ключевым атрибутам дочерней сущности |
| Пример ссылочной целостности: 1. child delete 2.child insert 3. child update 4.parent delete 5. parent insert 6. parent update |
Пример построения инфологической схемы БД
Задача:
Описать инфологическую схему фрагмента БД процессингового центра в нотации Чена. См. диаграмму DFD детализированный процесс 1.2
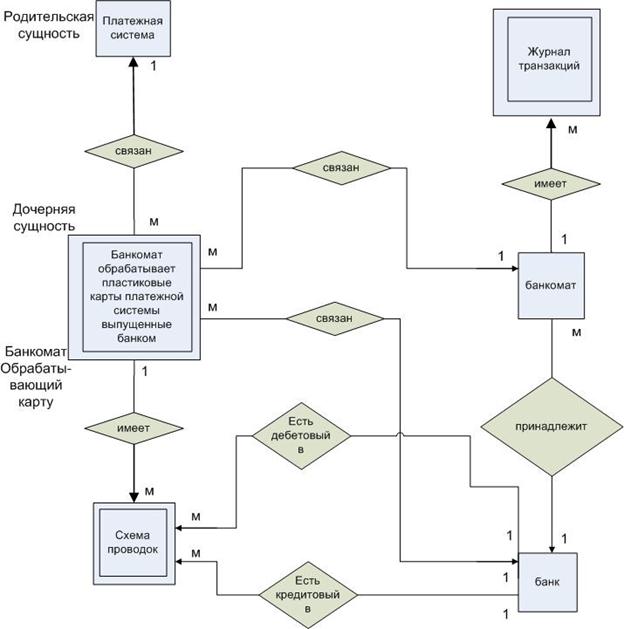
Здесь представлена инфологическая схема БД без описания атрибутов.
Примечание:
1) Здесь звездочка означает идентифицирующую связь. Это означает что ключ родительской сущности (1) добавляется ключевым атрибутам дочерней сущности (м). Это бывает необходимо, если ключевые атрибуты дочерней сущности в совокупности не являются уникальными (ключ всегда уникален).
2) Отсутствие звездочки в обозначении связи означает, что ключ родительской сущности (1) добавляется не к ключевым атрибутам (м). Это следует делать, если ключевые атрибуты дочерней сущности в совокупности являются уникальными.
3) Не идентифицирующая связь является предпочтительной, так как позволяет минимизировать число атрибутов в ключе дочерней сущности.
Лекция 5
Действия (1) и (2) обеспечивают возможность связи сущностей по общим атрибутам, также обеспечивают возможность объединения сущностей без потерь. Указанные средства часто выполняются автоматически.
Атрибуты сущностей БД.
| Платежная система | # Ключ платежной системы Наименование Лимит наличных |
| Банк | # Ключ Банка БИК Наименование Адрес к/с в РКЦ № Лицензии |
| Банкомат | # Ключ Банкомата Ключ банка v № Банкомата Лимит Банкомата Текущее число банкнот |
| Бок | # Ключ БОК Ключ платёжной системы v Ключ Банка v Ключ Банкомата v |
| Журнал транзакций | # Номер операции # Дата # Ключ банкомата v Номер пластиковой карты Банк иметент Сумма |
| Схема проводки | # Номер проводки транзакции # Ключ Бок Ключ банка(дебет) v Признак счёта дебет (0-лора, 1-Ностра, 2 –карт – счёт) Ключ банка(кредит) v Признак счёта кредит (0-лора, 1-Ностра, 2 –карт – счёт) Формула расчёта суммы |
Для уменьшения числа атрибутов в ключе можно использовать последовательность, а отмеченные атрибуты сделать неключевыми.
# - Ключевые атрибуты
v – атрибуты наследованные от родительских сущностей
Пример формирования платёжного документа в расчётный банк по атрибутам «Схема проводки».
Пусть записи «Схема проводки» имеют следующий вид:
· Номер проводки
· Ключ БОК
· Ключ Сбербанка
· 2 – карт-счёт
· ключ Банка Москвы
· 2 – счёт по обслуживанию банкомата
· 102 – 100% сумма + 2% комиссия
Предположим, пользователь карточки сбербанка запросил в банкомате Банка Москвы сумму равную 1000, тогда процессинговый центр на основании описания записи сформирует следующий платежный документ, который будет передан в расчётный банк.
ДЕБЕТ: Бик сбербанка
Номер пластиковой карты
КРЕДИТ: Бик Банка Москвы
Номер банкомата
СУММА: 1020руб.
Отличия нотации Чена от ErWin
| Нотация Чена | ErWin |
1. Обозначение сущности

|

|
2. Обозначение связи
а)Идентифицирующая
 б) неидентифицирующая
б) неидентифицирующая
 в)М:М
в)М:М

|

 Logical
Logical
 Phisical
Phisical

|
3) Категоризация сущностей

|

|
При разработки инфологической схемы проектировщик руководствуется тремя абстракциями.
Агрегация – это объединение реквизитов в отдельный экземпляр.
Реквизиты Код01 VISA Лимит 2000
Агрегат 
Обобщение – это объединение агрегатов в сущность.
Агрегат 

Сущность 
Ассоциация – это связь между сущностями
2. Построение логического плана выполнения SQL-запроса в СУБД.
Построение логического плана
При построении логического плана выполнения SQL-запроса выполняются следующие действия:
1. Запрос преобразуется в формулу реляционной алгебры (явно или неявно).
2. Выполняется преобразование (оптимизация) этой формулы.
Дата добавления: 2015-04-21; просмотров: 258; Мы поможем в написании вашей работы!; Нарушение авторских прав |