КАТЕГОРИИ:
АстрономияБиологияГеографияДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРиторикаСоциологияСпортСтроительствоТехнологияФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Доступ к данным из CGI, API программ
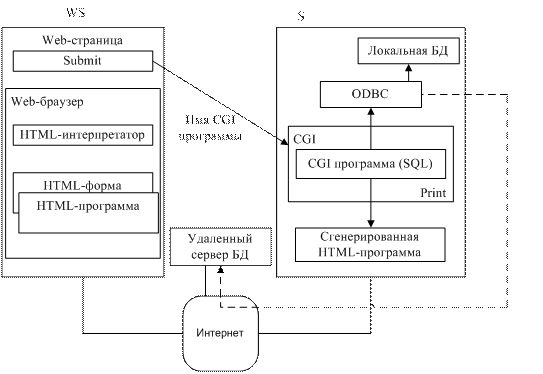
По url читается HTML форма, она интерпретируется и на экране появляется web-страница с полями/формами. На сервер передается имя CGI программы и значения заполненных полей. На web-сервере запускаются соответствующие CGI программы (как задача ОС). Если при выполнении этой программы встречается SQL-оператор, то он через ODBC интерфейс передается на локальный сервер БД либо на удаленный сервер. Результат выполнения SQL-оператора выполняется в CGI программе, она его обрабатывает и с помощью команды print генерирует html-программу (в нее включаются результаты поиска в БД). Эта html-программа возвращается на рабочую станцию, там интерпретируется и отображается на экране.
Преимущества CGI:
ü Web-сервер выступает в качестве сервера приложения (администрирование выполняется централизованно).
ü CGI интерфейс унифицирован и реализован во всех серверах.
ü Для доступа к БД можно использовать любой web-браузер.
Недостатки:
ü Каждая CGI программа выполняется как процесс ОС. Инициализация задачи ОС и переключение между ними занимает очень много времени, т.к. требуется переключение между блоками управления страницами.
ü CGI программа не поддерживает контекст связи с БД, т.е. БД открывается при каждом вызове CGI программы.
ü Генерируемая форма имеет небольшие выразительные возможности.
Для устранения 1-го недостатка в настоящее время используют API-интерфейсы, например ASP, PHP, JSP. API программы выполняются как отдельные потоки, но в рамках задачи web-сервера, т.е. в рамках одной задачи ОС.
Преимущества API:
ü Они выполняются быстрее, чем CGI программы (нет переключения между задачами ОС).
ü ASP вместе с некоторыми дополнениями (Remote scripting, scriptlet) позволяют поддерживать контекст с БД
Недостатки:
ü API программы разных производителей не совместимы между собой
ü API интерфейсы и соответствующие API программы зависят от платформы
-------------------------------------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------------------------------------
БИЛЕТ 29
1. Метод сортировки-слияния соединения таблиц (SMJ).
Метод сортировки-слияния (SMJ – Sort Merge Join)
Соединение таблиц включает следующие шаги:
1. Соединяемые таблицы сортируются по атрибуту соединения (обозначим его через "а").
2. Организуется вложенный цикл, где выполняется сравнение значений атрибутов соединения.
Условием соединения может быть только равенство атрибутов соединения.
Пример выполнения соединения методом сортировки-слияния приведен на рис. 1.15.

Рис. 1.15. Метод соединения SMJ.
Выполняется сравнение записей, на которые указывают указатели таблиц Q1 и Q2 . Перемещение указателей выполняется следующим образом: если выполняется условие "<", то осуществляется перемещение указателя Q1 к следующей записи; если выполняется условие ">", то к следующей записи перемещается указатель Q2 ; при "=" указатели не перемещается и выполняется сравнение со следующей записью таблицы Q2.
Будем полагать, что используются левосторонние деревья и каналы. Схема назначения буферов приведена на рис. 1.16.

Рис. 1.16. Схема назначения буферов.
Формулы для оценки стоимости соединения SMJ имеют следующий вид.
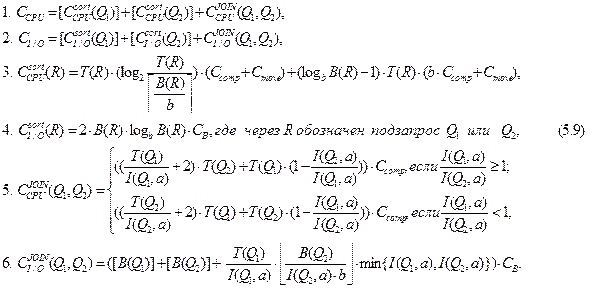
Здесь
T(Q1), T(Q2) – число кортежей в таблицах Q1 и Q2;
B(Q1), B(Q2) – число блоков в таблицах Q1 и Q2;
I(Q1,a), I(Q2,a) – мощности атрибутов соединения "а" в таблицах Q1 и Q2;
b – число блоков в ОП, отводимых под сортировку таблицы Q1 или Q2;
Ccomp – время соединения двух кортежей из таблиц Q1 и Q2 в ОП;
Cmove – время перемещения одного кортежа в ОП при сортировке;
CB – время чтения/записи одного блока на диск;
 - округление с избытком;
- округление с избытком;
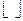 - округление с недостатком;
- округление с недостатком;
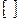 - не учитывается, если таблицы были уже отсортированы перед началом соединения.
- не учитывается, если таблицы были уже отсортированы перед началом соединения.
Некоторые формулы требуют пояснений. Рассмотрим сначала, как выполняется сортировка записей достаточно большой таблицы.
Блоки 1¸b таблицы R читаются в буфер (рис. 1.17) и записи этих блоков сортируются. Результат сортировки сохраняется в виде файла. Затем читаются следующие "b" блоков (b¸2b, см. рис. 1.17) и их записи также сортируются, результат сортировки сохраняется во втором файле и т.д.
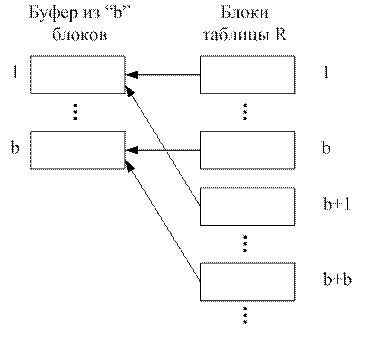
Рис. 1.17. Чтение большой таблицы в буфер из b блоков.
Сохранённые файлы представлены в виде уровня 1 на рис. 1.18.
Известно, что число операций сравнений и перемещений при сортировке пропорционально величине 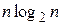 , где
, где 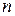 - число сортируемых записей.
- число сортируемых записей. 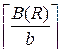 - это количество файлов уровня 1. Поэтому для одного файла
- это количество файлов уровня 1. Поэтому для одного файла 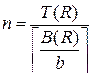 . С учётом числа файлов получаем первое слагаемое в формуле 3 (см. выражения (5.9)).
. С учётом числа файлов получаем первое слагаемое в формуле 3 (см. выражения (5.9)).
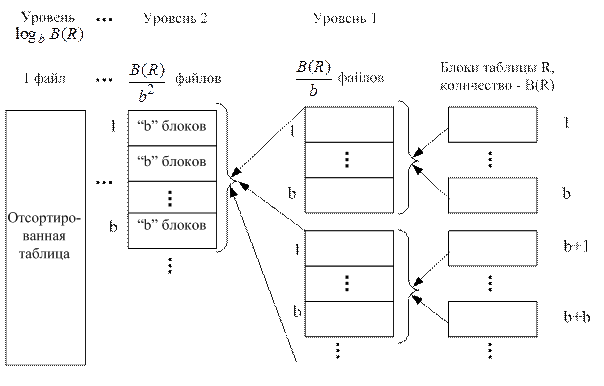
Рис. 1.18. Последовательное укрупнение отсортированных промежуточных файлов.
Далее из 1-го файла уровня 1 записи читаются в 1-й блок буфера, из 2-го файла уровня 1 записи читаются во 2-й блок и т.д., и из b-го файла уровня 1 записи читаются в b-й блок (рис. 1.19). В каждом блоке записи уже отсортированы на предыдущем этапе. Поэтому сравниваются первые записи этих блоков по атрибуту сортировки (b сравнений). Запись с минимальным значением атрибута перемещается в файл (одно перемещение). Остальные записи соответствующего блока сдвигаются вверх (блок работает как стек). Затем снова сравниваются первые записи b блоков по атрибуту сортировки и т.д. Если записи в каком-либо блоке исчерпаны, то в этот блок подгружаются записи из связанного с ним файла. После обработки таким способом b файлов уровня 1 будет сформирован файл уровня 2 (см. рис. 1.18), записи в котором отсортированы. Далее в блоки буфера подгружаются записи следующих b файлов уровня 1 и т.д.
По аналогичной схеме (см. рис. 1.19) объединяются файлы уровня 2 и т.д. В конце концов, будет сформирован один отсортированный результирующий файл (см. рис. 1.18). Количество уровней L может быть получено из уравнения 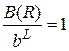 (число файлов на самом нижнем уровне равно 1), т.е.
(число файлов на самом нижнем уровне равно 1), т.е. 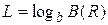 .
.
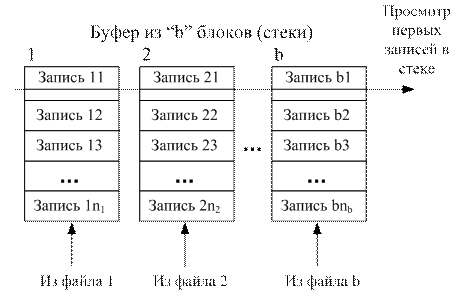
Рис. 1.19. Сортировка записей из b промежуточных файлов.
На каждом уровне (кроме последнего) по описанной выше схеме (см. рис. 1.19) обрабатываются все записи таблицы R (их число равно T(R)). Это объясняет второе слагаемое в формуле 3. В файлах каждого уровня хранятся B(R) блоков. Это объясняет формулу 4. Здесь коэффициент 2 учитывает, что каждый файл каждого уровня записывается на диск, а потом читается.
Чтение блоков таблицы R с диска (см. рис. 1.17) учитывается в стоимости выбора записей из исходной таблицы.
В формуле 5 первое слагаемое определяет процессорное время сравнения соединяемых записей. Если 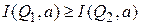 , то каждая запись из
, то каждая запись из 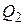 (их число равно
(их число равно 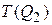 ) сравнивается и соединяется с
) сравнивается и соединяется с 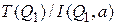 записями из
записями из 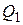 (т.е. с числом записей из , приходящихся на одно значение атрибута соединения). Константа 2 учитывает сравнения записей при перемещении указателей. Второе слагаемое в формуле 5 связано с холостыми проверками. Количество таких сравнений равно числу записей в , у которых значение атрибута соединения отличается от всех значений атрибута "а" в (мощность таких значений атрибута "а" в равно
(т.е. с числом записей из , приходящихся на одно значение атрибута соединения). Константа 2 учитывает сравнения записей при перемещении указателей. Второе слагаемое в формуле 5 связано с холостыми проверками. Количество таких сравнений равно числу записей в , у которых значение атрибута соединения отличается от всех значений атрибута "а" в (мощность таких значений атрибута "а" в равно 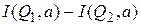 ).
).
В формуле 6 учитывается возможное чтение таблиц и после сортировки (первые два слагаемых), а также многопроходной вариант соединения, если не все блоки с одинаковыми значениями атрибута связи помещаются в буфере из b блоков (третье слагаемое).
2. Предложение SELECT языка SQL (коррелированный подзапрос, случай использования одной и той же таблицы в подзапросе и внешнем запросе).
- Коррелированный подзапрос.
Пример:
Выдать номера поставщиков, которые поставляют детали с номером P2.
Решение:
SELECT имя
FROM S
WHERE ‘P2’ IN
(SELECT номер_детали
FROM SPJ
WHERE номер_поставщика = S.номер_поставщика);
Если атрибут используется без префикса (в данном случае номер_поставщика), то он принадлежит таблице, указанной за ключевым словом FROM соответствующего подзапроса.
Здесь внутренний подзапрос зависит от внешнего.
На логическом уровне запрос выполняется следующим образом:
- просматриваются все записи таблицы S
- для каждой записи выполняется внутренний подзапрос.
- если P2 принадлежит найденному множеству номеров деталей значит имя поставщика выводится на экран.
- Использование одной и той же таблицы во внешнем и внутреннем запросах.
Пример:
Выдать номера поставщиков, которые поставляют по крайней мере одну деталь, поставляемую поставщиком с номером S2.
Решение:
SELECT номер_поставщика
FROM SPJ
WHERE номер_детали IN
(SELECT номер_детали
FROM SPJ
WHERE номер_поставщика = ‘S2’);
- Подзапросы можно использовать в качестве таблицы в выражении FROM.
Пример:
Выдать номера поставщиков, которые поставляют по крайней мере одну красную деталь.
Решение:
SELECT имя
FROM S, (SELECT номер_поставщика
FROM SPJ,P
WHERE
SPJ.номер_детали = SPJ.номер_детали
AND цвет= ‘красный’) NP
WHERE S.номер_поставщика = NP. номер_поставщика;
-------------------------------------------------------------------------------------------------------------------------
БИЛЕТ 30
1. Методы асинхронного тиражирования данных.
Дата добавления: 2015-04-21; просмотров: 371; Мы поможем в написании вашей работы!; Нарушение авторских прав |