КАТЕГОРИИ:
АстрономияБиологияГеографияДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРиторикаСоциологияСпортСтроительствоТехнологияФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
СТАТИСТИЧЕСКИЕ МЕТОДЫ АНАЛИЗА ВЗАИМОСВЯЗЕЙ СОЦИАЛЬНО-ЭКОНОМИЧЕСКИХ ЯВЛЕНИЙ
Цель: сформировать представление о методах измерения стохастических связей, специфических черт, преимуществ и ограничений применения этих методов.
Задачи: представить классификацию видов и методов измерения связей, раскрыть особенности корреляционного и регрессионного методов анализа, а также непараметрических методов изучения связей.
Функциональные и статистические зависимости. Общие принципы и задачи статистического изучения связи. Качественный анализ при изучении зависимостей
В математическом смысле слово «зависимость» означает функциональную зависимость, при которой каждому значению признака-фактора X соответствует вполне определенное значение признака-результата Y (рис. 4.1).



Рис. 4.1. Графическое отображение функциональной связи.
Однако функциональные зависимости не исчерпывают всех возможных видов взаимосвязи между явлениями. Большинство зависимостей, с которыми приходится сталкиваться в экономике (например, зависимость выпуска продукции предприятия от числа рабочих, прибыль предприятия от затрат на рекламу), имеют не функциональную природу. Такого рода зависимости носят название корреляционных или стохастических. Наглядное представление такой связи дает графическое построение, называемое корреляционным полем (рис. 4.2). Для изучения связи между признаками X и Y проводится статистическое наблюдение над некоторой совокупностью, в ходе которого фиксируются значения этих величин. Затем все элементы совокупности изображаются в системе координат.



Рис. 4.2. Графическое отображение стохастической связи.
Таким образом, можно дать определения различным видам связей в статистике.
Статистическая (стохастическая) связь – это такая связь между признаками, при которой для каждого значения признака-фактора Х признак-результат Y может в определенных пределах принимать любые значения с некоторыми вероятностями; при этом его статистические (обобщающие) характеристики (например, среднее значение) изменяются по определенному закону.
Модель стохастической связи может быть представлена в общем виде уравнением:
Y=f(X,u),
где Y - фактическое значение результативного признака;
f(X) - часть результативного признака, сформировавшаяся под воздействием фактора Х (или множества факторов: Y=f(X1,...,Xm);
u - случайная составляющая, часть результативного признака, возникшая вследствие действия прочих (неучтенных) факторов, а также ошибок измерения признаков.
Например, уровень успеваемость студентов по статистике стохастически связан с целым комплексом факторов: склонностью к точным наукам; временем, затраченным на подготовку к предмету; состоянием здоровья студента и др. Полный перечень факторов неизвестен. Кроме того, неодинаково действие любого известного фактора на результат. Например, при одной и той же успеваемости, разные студенты затрачивают неодинаковое время на подготовку. В результате – при одинаковых возможностях наблюдается вариация значений успеваемости студентов.
Корреляционная связь - частный случай статистической связи, при которой с изменением значения признака-фактора Х среднее значение признака-результата Y закономерно изменяется: М(YçX)=f(X) или М(YçX1, X2, .., Xm)=f(X1, X2, ...,Xm) , m – количество факторов, М (YçX)– условное математическое ожидание.
Понятие «корреляция» было введено английскими статистиками. В переводе оно означает подобие связи (в смысле функциональной связи). Relation по-английски - жестко детерминированная (функциональная) связь.
Функциональная связь – такая связь, при которой для каждого значения признака-фактора признак-результат принимает одно или несколько строго определенных значений. Она имеет место, когда все факторы, действующие на результативный признак, известны и учтены в модели и ошибки измерения отсутствуют. Модель функциональной связи может быть представлена как:
Y=f(X).
При изучении корреляционных зависимостей необходимо решать следующие задачи:
1. установление факта зависимости. На начальном этапе необходимо выяснить, существует ли какая-либо зависимость между рассматриваемыми признаками фактором (X) и результатом (Y). Если зависимости не существует, то исследование на этом заканчивается, если же зависимость существует, исследователь переходит к следующим задачам;
2. установление формы, характера зависимости и определение ее количественных характеристик. На данном этапе, во-первых, определяется направление связи: прямая или обратная. При прямой связи направление изменения результата совпадает с направлением изменения признака-фактора. При обратной связи направление изменения результата противоположно направлению изменения признака-фактора. Например, чем выше квалификация рабочего, тем выше уровень производительности его труда (прямая связь). Чем выше производительность труда, тем ниже себестоимость единицы продукции (обратная связь). Во-вторых, определяется форма связи (вид функции f): линейная (прямолинейная) и нелинейная (криволинейная).
Линейная связь отображается прямой линией; криволинейная отображается кривой (параболой, гиперболой и т.п.). При линейной связи с возрастанием значения факторного признака происходит равномерное возрастание (убывание) значения результативного признака. При криволинейной связи с возрастанием значения фактора возрастание (убывание) результата происходит неравномерно (гиперболическая форма связи) или же направление его изменения меняется на обратное (параболическая форма связи). Наконец, определяется количество факторов, оказывающих влияние на результат, в соответствии с чем связи подразделяются на однофакторные (парные) и многофакторные;
3. оценка тесноты связи. Если задачи 1 и 2 имеют смысл и для функциональной, и для корреляционной зависимости, то измерение тесноты связи специфично именно для анализа корреляционных зависимостей. Для функциональных связей данное понятие лишено смысла, поскольку связь носит абсолютный, однозначный характер.
Порядок изучения статистической связи:
1. Качественный (содержательный) анализ связи. На этом этапе производят предварительный анализ направления и формы связи.
2. Сбор данных (статистическое наблюдение).
3. Эмпирический анализ связи.
4 Количественная оценка тесноты связи (корреляционный анализ).
5. Установление аналитической зависимости между признаками (регрессионный анализ):
5.1. выбор формы связи (вида аналитической зависимости);
5.2. оценка параметров уравнения регрессии;
5.3. оценка качества уравнения регрессии.
Эмпирическая регрессия. Дисперсионный анализ
Эмпирический анализ связисостоит в построении группировок (аналитической или комбинационной) и графиков.
Для анализа связи между признаками служат графики: корреляционного поля и эмпирической линии регрессии.
Корреляционное поле – точечный график, построенный в прямоугольной системе координат. Число точек равно числу единиц в совокупности. Каждая точка соответствует единице совокупности и имеет координаты по оси абсцисс – значение признака-фактора Х, а по оси ординат – значение признака-результата Y у данной единицы совокупности.
Для построения эмпирической линии регрессии требуются данные аналитической группировки. Эмпирическая линия регрессии – ломанная, построенная по данным аналитической группировки. Число точек у этой ломаной равно числу групп в аналитической группировке. Координаты точек: по оси Х – значение признака-фактора в группе (или середина интервала, если группировка интервальная), по оси Y – среднее значение признака-результата в группе.
Форма графиков корреляционного поля и эмпирической линии регрессии позволяет делать выводы о направлении, форме и тесноты связи. Если эмпирическая линия регрессии по своему виду приближается к прямой линии, то можно предположить наличие прямолинейной корреляционной связи между признаками. А если линия связи приближается к кривой, то это может быть связано с наличием криволинейной корреляционной связи.
Эмпирическая линия регрессии не дает значений результирующего признака, соответствующих отдельным значениям признака-фактора, данная зависимость не может быть точно описана какой-либо функцией. Эмпирическая регрессия отражает при этом главную тенденцию рассматриваемой зависимости.
Пусть, требуется построить эмпирическую линию регрессии и корреляционное поле по данным о 15 предприятиях розничной торговли для выявления зависимости между двумя признаками: Y – объем продаж за период (млн. руб.) и X – расходы на рекламу (млн. руб.). Исходные данные приведены в табл. 4.1.
Для построения корреляционного поля (рис. 4.3.) в прямоугольной системе координат отложим 15 точек, каждая из которых соответствует своей единице совокупности (предприятию). Координатами точек являются по оси абсцисс – значение признака-фактора (расходы на рекламу), по оси ординат – значение признака-результата (объем продаж за период).
Таблица 4.1
Исходные данные
| № п.п. | Расходы на рекламу, млн. руб. (X) | Объем продаж, млн. руб. (Y) |
Таблица 4.2
Аналитическая группировка предприятий
| Расходы на рекламу, млн.руб. | Середина интервала | Число предприятий | Средний по группе объем продаж, млн.руб. |
| 40—65 | 52,5 | 139,3 | |
| 65—80 | 72,5 | 166,3 | |
| 80—115 | 97,5 | 243,6 | |
| Итого | — | — |
Для построения эмпирической линии регрессии (рис. 4.3.) нам потребуются данные аналитической группировки (табл. 4.2). Число точек эмпирической линии регрессии равно числу групп (в нашем примере 3). Координатами точек являются по оси абсцисс – середина интервала по X в группе, а по оси ординат – среднее значение признака-результата Y в группе.
Результаты построения графиков корреляционного поля и эмпирической линии регрессии представлены на рис. 4.3.



Рис. 4.3. Корреляционное поле и эмпирическая линия регрессии.
Анализируя эмпирическую линию регрессии и корреляционное поле, можно сделать вывод о прямой, близкой к линейной зависимости между признаками.
Если статистическая совокупность разбита на группы по какому-либо признаку, то для оценки влияния различных факторов, определяющих колеблемость индивидуальных значений признака, можно воспользоваться разложением дисперсии на составляющие: на межгрупповую и внутригрупповую дисперсии.
Если рассчитать дисперсию признака по всей изучаемой совокупности, т.е. общую дисперсию, то полученный показатель будет характеризовать вариацию признака, как результат влияния всех факторов, определяющих индивидуальные различия единиц совокупности. Если же поставить дальнейшую задачу - выделить в составе общей дисперсии ту ее часть, которая обусловлена влиянием какого-либо определенного фактора, то следует разбить изучаемую совокупность на группы, положив в основу группировки интересующий нас фактор. Затем нужно изучить раздельно вариацию признака внутри однородных в отношении данного фактора групп и изменения в величине признака от группы к группе. Выполнение такой группировки позволяет разложить общую дисперсию признака на две дисперсии, одна из которых будет характеризовать часть вариации, обусловленную влиянием фактора, положенного в основу группировки, а вторая – вариацию, происходящую под влиянием прочих факторов.
На основе этого подхода строится дисперсионный анализ. Он позволяет установить оказывает ли существенное влияние некоторый (чаще всего качественный) фактор (имеющий k уровней) на изучаемый признак. То есть дисперсионный анализ используется для проверки гипотезы о связи.
Дисперсионный анализ часто применяется совместно с результатами аналитической группировки. При этом ставится задача оценки существенности различий средних значений признака-результата в группах, выделенных по признаку-фактору.
Для решения данной задачи рассчитывают F-критерий:

где 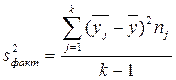 – это исправленная (скорректированная на число степеней свободы) межгрупповая дисперсия;
– это исправленная (скорректированная на число степеней свободы) межгрупповая дисперсия;
 - это исправленная (скорректированная на число степеней свободы) внутригрупповая дисперсия.
- это исправленная (скорректированная на число степеней свободы) внутригрупповая дисперсия.
Эта запись предполагает, что s2факт> s2ост. Как правило, мы получаем именно такое соотношение.
По таблицам распределения Фишера находят критическое значение Fкр, задаваясь уровнем значимости (вероятностью ошибки 1-ого рода) α и числами степеней свободы: df1= k-1, df2=n-k.
Если Fнабл>F кр(a, df1, df2), то можно утверждать, что влияние признака-фактора является существенным или статистически значимым.
Результаты дисперсионного анализа заносят обычно в таблицу (табл. 4.3)
Таблица 4.3
Результаты дисперсионного анализа
| Источник вариации | SS-сумма квадратов отклонений | Df-число степеней свободы | MS-сумма квадратов на одну степень свободы | F-наблюдаемое значение критерия |
| Между группами | 
| k-1 | MSмгр= SSмгр/dfмгр | MSмгр/MSвгр |
| Внутри групп | 
| n-k | MSвгр= SSвгр/dfвгр | |
| Итого | 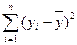
| n-1 |
Корреляционный анализ
Количественная оценка тесноты связи по эмпирическим данным состоит в расчете показателей тесноты связи:эмпирического коэффициента детерминации, эмпирического корреляционного отношения, коэффициента Фехнера, коэффициента линейной парной корреляции.
Эмпирический коэффициент детерминации или эмпирическое дисперсионное отношение, r2-показатель, характеризующий процент (долю) вариации признака-результата, обусловленную признаком-фактором. Рассчитывается по данным аналитической группировки, как отношение межгрупповой дисперсии признака-результата (dy2) к общей дисперсии признака-результата (sy2):

 .
.
Эмпирическое корреляционное отношение, r - показатель тесноты связи, рассчитываемый как корень из эмпирического коэффициента детерминации. Область допустимых значений эмпирического корреляционного отношения от 0 до +1. При достаточно тесной связи между признаками эмпирический коэффициент детерминации стремится к 1. При слабой связи – к нулю.
Заметим, что сама по себе величина показателя силы влияния фактора на результат не является доказательством наличия причинно-следственной связи между исследуемыми признаками, а является оценкой степени взаимной согласованности в изменениях признаков. Установлению причинно-следственной зависимости должен обязательно предшествовать анализ качественной природы явлений.
Пусть, имеется аналитическая группировка предприятий розничной торговли по расходам на рекламу (X) (признак-результат – объем продаж (Y)) (табл. 4.2). Требуется оценить тесноту связи между признаками X и Y с помощью коэффициента детерминации и эмпирического корреляционного отношения. Решение:
 .
.
Рассчитаем межгрупповую дисперсию:

Рассчитаем внутригрупповые дисперсии:
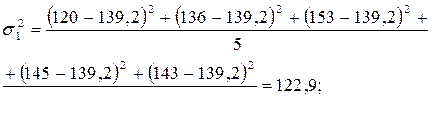

Рассчитаем остаточную дисперсию:

Общая дисперсия равна 1953,3+652,3=2605,6(полученное значение совпадает со значением дисперсии, рассчитанным по несгруппированным данным).
Коэффициент детерминации рассчитывается следующим образом:

Эмпирическое корреляционное отношение рассчитывается следующим образом:

Так как значение r близко к единице, то связь между признаками Расходы на рекламу и Объем продаж довольно тесная.
Коэффициент Фехнера, Кф - показатель тесноты линейной связи, рассчитываемый по формуле:
 ,
,
где С/Н – число совпадений / несовпадений знаков отклонений Х от своего среднего значения и Y от своего среднего значения. Значения данного показателя изменяются в пределах от -1 до +1.
Дата добавления: 2014-12-23; просмотров: 804; Мы поможем в написании вашей работы!; Нарушение авторских прав |