КАТЕГОРИИ:
АстрономияБиологияГеографияДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРиторикаСоциологияСпортСтроительствоТехнологияФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Загальна задача перевірки гіпотез
Одним із найважливіших розділів математичної статистики є статистична перевірка гіпотез. При цьому під гіпотезою розуміють певні припущення про вигляд невідомого розподілу або про невідомі параметри деяких відомих розподілів досліджуваної величини. Такі гіпотези називають статистичними. До проблеми висування статистичної гіпотези приводять такі, досить часто виникаючі задачі, як порівняльна оцінка різних методів спостережень (вимірювань) за їх точністю, економічністю, досконалістю методики, а також порівняння особливостей конструкції геодезичних інструментів та приладів.
Питання про те, за якою ознакою і в яких відношеннях доцільні такі порівняння, цілком відносяться до компетенції тих спеціальних областей геодезії, фотограмметрії, гравіметрії, картографії, астрономії, в яких виникають ці задачі. Однак, при наявності явища розсіювання ознак, за якими необхідно виконати порівняльну оцінку (наприклад, точність вимірювань або якість інструментів), обгрунтований висновок можна отримати лише шляхом науково проведеного аналізу статистичної інформації.
Статистичні дані при цьому розглядаються як деякі вибірки з генеральних сукупностей, які інформують про поведінку випадкових величин, що цікавлять дослідника і дозволяють зробити певні висновки про закони розподілу цих величин. У більшості випадків можна не сумніватися в тому, що величини, які порівнюють, мають однаковий закон розподілу ( нормальний, біномінальний тощо), але своєрідність закону розподілу кожної із цих величин полягає, як правило, в різниці значень параметрів: математичного сподівання, дисперсії і т.д. Отже, при зміні параметрів і знаходять відображення відмінності в якості методу вимірювань, інструментів тощо, які виявляються шляхом співставлення статистичних даних.
Наведемо приклади такого аналізу статистичних даних.
Нехай порівнюються дві серії вимірювань однієї і тієї ж величини двома різними вимірювальними приладами. Співставляючи емпіричні дисперсії в цих серіях, можна легко оцінити, наскільки точність одного з приладів відрізняється від точності іншого.
Або нехай порівнюються дві чи багато серій вимірювань однієї і тієї ж величини, які виконані приладами однакової точності але різними методами в однакових фізичних умовах. Науково обгрунтовані висновки про переваги одного методу над іншими можна отримати співставленням середніх арифметичних результатів спостережень та емпіричних дисперсій.
Отже, перевірка гіпотез полягає в порівнянні статистичних характеристик, які є оцінками параметрів законів розподілу. Інакше кажучи, з припущень про закони розподілу або їх параметри (зі “статистичних гіпотез”) приходять до певних наслідків і розглядають наскільки вони виправдовують себе на практиці. Ці наслідки мають характер ймовірнісних міркувань про поведінку деяких статистичних характеристик при зроблених припущеннях.
Перевірка полягає в обчисленні значень цих характеристик (статистик) за даними спостережень і в порівнянні їх з тим, що було отримано на основі зроблених припущень. Такі статистики називаються критеріями перевірки статистичних гіпотез. Вони є випадковими величинами, значення яких визначаються з вибірки.
Для критеріїв перевірки вибирають так звані рівні значущості, які, як правило, зображаються в %-ах (наприклад q = 5%, 2%, 1% і т. п.) і відповідають подіям, які в даних умовах досліджень вважаються практично неможливими (правда, з деяким ризиком). Рівні значущості визначають критичну область даного критерія, ймовірність a потрапляння в яку у випадку, коли сформульована гіпотеза є вірною, точно дорівнює рівневі значущості, тобто a = q/100.
Значення критеріїв, які потрапляють ззовні критичної області, утворюють додаткову до неї область “допустимих значень”, ймовірність потрапляння до якої критерію при справедливості висунутої гіпотези дорівнюватиме 1 – q / 100. Ця подія вважається практично достовірною при тих самих умовах.
Отже, якщо значення нашого критерію, яке обчислено за даними спостережень, потрапляє в критичну область, то висунута гіпотеза відхиляється (спростовується).
Поряд з гіпотезою, яка висувається, завжди формулюють другу гіпотезу, яка суперечить першій. Першу (основну) називають нульовою гіпотезою і позначають її H0, а другу – конкуруючою (альтернативною) і позначають H1.
Наприклад, якщо нульова гіпотеза полягає в тому, що математичне сподівання a нормального розподілу дорівнює 2,0, то конкуруюча гіпотеза може стверджувати (припускати) що a ¹ 2,0. Це позначають так:
H0: a = 2,0; H1: a ¹ 2,0.
Таким чином, якщо гіпотеза H0відхиляється, то приймається альтернативна гіпотеза H1.
Якщо значення критерію опиняється в області допустимих значень, тоді неможливо стверджувати, що гіпотеза H0є справедливою. Можна тільки говорити, що спостережуване значення критерію не суперечить висунутій гіпотезі H0, тобто її можна вважати справедливою доти, доки більше поширені дослідження (наприклад, при більших обсягах вибірок або з допомогою іншого критерію) не приведуть до протилежного висновку.
Чим менший рівень значущості , тим менша ймовірність не прийняти гіпотезу, яка перевіряється, коли вона є вірною, або, як говорять, “зробити помилку першого роду”. Але зі зменшенням рівня значущості через те, що зменшується чутливість критерію, розширюється область його допустимих значень і збільшується ймовірність зробити так звану “помилку другого роду”, тобто прийняти гіпотезу, яка перевіряється, коли вона є невірною, тобто вірною є альтернативна гіпотеза, яка може бути тільки наближеною до першої і забезпечує більшу ймовірність потрапляння критерія в область допустимих значень.
Отже, рівень значущості критерія перевірки гіпотези контролює лише помилки першого роду, але зовсім не визначає степінь ризику, який пов’язаний із прийняттям невірної гіпотези (тобто можливістю зробити помилку другого роду).
Нехай a – ймовірність помилки першого роду, а b – ймовірність помилки другого роду. Тоді можна сказати, що для великої кількості вибірок частка хибних висновків дорівнює a, якщо справедлива гіпотеза H0, та дорівнює b, якщо справедлива гіпотеза H1(альтернативна). Помилки першого і другого роду можна подати у вигляді такої таблиці:
Таблиця 6.4

Для даного рівня значущості можна по різному встановлювати критичну область, яка б гарантувала цей рівень. Наприклад, нехай маємо деякий показник X, нормально розподілений із густиною f(x; mx; sx), який приймається за критерій перевірки статистичної гіпотези. Вибираємо рівень значущості q = 5%. Можна розглядати такі критичні області (див. Рис. 6.8):

Рис. 6.8
I. Область великих додатних відхилень (правобічна)
.  (6.41)
(6.41)
Через те, що
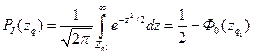 ,
,
то за таблицею для функції Лапласа (див. Додаток, табл.2)


Зауваження. Тут і далі zq– критична точка, яка визначає межу критичної області.
II. Область великих від’ємних відхилень (лівобічна).
 . (6.42)
. (6.42)
Із вище наведених міркувань .
III. Область великих за абсолютною величиною відхилень (двобічна).
 . (6.43)
. (6.43)
У цьому випадку
 .
.
За таблицею для функції Лапласа (див. Додаток, табл.2) із використанням співвідношення знаходимо звідки
IV. Область малих за абсолютною величиною відхилень (двобічна).
 . (6.44)
. (6.44)
Така ймовірність дорівнюватиме
 .
.
За таблицею (див. Додаток, табл.2) та значенням отримаємо
Задача найкращого вибору критичної області найчастіше розв‘язується так, щоб критерій перевірки гіпотези мав найбільшу чутливість, тобто щоб забезпечити найбільшу ймовірність потрапляння критерію перевірки у критичну область, коли справедливою є конкуруюча гіпотеза H1до основної H0. Ця ймовірність називаєтьсяпотужністю критерію. Чим більша потужність критерію, тим менша ймовірність b зробити помилку другого роду.
Таким чином, потужність критерію – це ймовірність потрапляння самого критерію (певної статистики) у критичну область при умові, що справедливою є альтернативна гіпотеза, інакше кажучи, нульова гіпотеза, H0 буде спростована, якщо вірною є гіпотеза H1.
Із наведених міркувань ясно, що завжди існує великий вибір критичної області. Але з точки зору здорового глузду критичну область треба будувати такою, щоб потужність критерію була б максимальною (дійсно, тоді зменшується ймовірність b зробити помилку другого роду). Таким чином, потужність критерію контролює помилки другого роду.
Зменшити обидві ймовірності a та b одноразово неможливо: якщо зменшувати a, то b автоматично збільшується.
Відповідь на питання “як краще?” залежить від “важкості наслідків” помилок першого і другого роду в кожній конкретній задачі. Наприклад, якщо помилка першого роду викликає більші втрати, а другого роду – менші. Тоді треба прийняти якомога менше a. Існує теорема неймана-Пірсона, за якою можна будувати критичну область для найменшої ймовірності b для вже обраної ймовірності a (тобто отримати максимальну потужність критерію). На практиці така задача в основному розв’язується інтуїтивно.
Слід зауважити, що спростовують гіпотезу більш категорично, ніж приймають. Із досвіду відомо, що достатньо навести один приклад, який суперечить деякому загальному твердженню, і воно спростовується. Потрапляння обчисленого критерію у критичну область є фактом, який можна сприймати як такий приклад, що суперечить гіпотезі H0і дозволяє її відхилити.
Розглянемо тепер конкретні статистичні гіпотези, які перевіряють при розв’язуванні різних виробничих (геодезичних в тому числі) задач.
Дата добавления: 2014-12-03; просмотров: 524; Мы поможем в написании вашей работы!; Нарушение авторских прав |