КАТЕГОРИИ:
АстрономияБиологияГеографияДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРиторикаСоциологияСпортСтроительствоТехнологияФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Методы обнаружения гетероскедастичности
1. Графический
Для скалярных (одномерных) моделей осуществляется графический анализ зависимости  . Для множественной регрессии такие зависимости строятся для каждой объясняющей переменной
. Для множественной регрессии такие зависимости строятся для каждой объясняющей переменной  отдельно или по оси абсцисс откладывают значения
отдельно или по оси абсцисс откладывают значения  . Наличие гетероскедастичности проявляется в виде тенденции изменения распределения
. Наличие гетероскедастичности проявляется в виде тенденции изменения распределения  . Однако в связи со случайным характером объясняемой переменной по одной конкретной реализации судить о гетероскедастичности можно только предварительно. Наиболее объективно наличие гетероскедастичности можно подтвердить с помощью специальных тестов.
. Однако в связи со случайным характером объясняемой переменной по одной конкретной реализации судить о гетероскедастичности можно только предварительно. Наиболее объективно наличие гетероскедастичности можно подтвердить с помощью специальных тестов.
2. Тест ранговой корреляции Спирмена
Тест ранговой корреляции Спирмена используется, когда есть предположение, что дисперсия отклонения будет либо увеличиваться, либо уменьшаться с увеличением значений фактора Х. Этот тест заключается в проверке коррелированности абсолютных значений остатков  и значений
и значений  , т.е. проверяется не просто зависимость между ними, а ее приближение к линейной.
, т.е. проверяется не просто зависимость между ними, а ее приближение к линейной.
Коэффициент ранговой корреляции Спирмена вычисляется по формуле
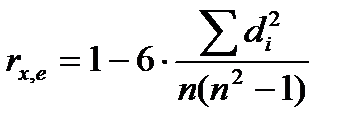 , (4.1)
, (4.1)
где  - число наблюдений;
- число наблюдений;  - разность между рангами
- разность между рангами  .
.
Доказано, что если коэффициент корреляции  (для генеральной совокупности) равен нулю, то статистика
(для генеральной совокупности) равен нулю, то статистика
 (4.2)
(4.2)
имеет распределение Стьюдента с числом степеней свободы 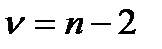 .
.
Если 
 , то гипотеза =0 отклоняется в пользу гипотезы
, то гипотеза =0 отклоняется в пользу гипотезы  , т.е. гетероскедастичность присутствует.
, т.е. гетероскедастичность присутствует.
Для множественной регрессии такая проверка осуществляется для каждой объясняющей переменной.
3. Тест Голдфелда-Квандта
При применении данного теста делается предположение, что дисперсия остатков возрастает пропорционально квадрату переменной  . Этот тест в принципе дополняет тест Спирмена, так как здесь также предполагается, что отклонение
. Этот тест в принципе дополняет тест Спирмена, так как здесь также предполагается, что отклонение  пропорционально .
пропорционально .
Смысл теста
Шаг 1. Упорядочение  переменных Х по возрастанию.
переменных Х по возрастанию.
Шаг 2. Разделение совокупности Х на две группы с малыми и большими значениями, исключая из рассмотрения С - центральных наблюдений (С должно быть примерно равно четверти общего количества наблюдений). По каждой из этих выборок, объемами  , строятся уравнения парной регрессии, из которых определяются остаточные суммы квадратов
, строятся уравнения парной регрессии, из которых определяются остаточные суммы квадратов
 ;
;  . (4.3)
. (4.3)
Шаг 3. Определяется F-статистика
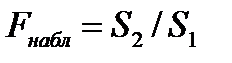 , (4.4)
, (4.4)
значение которой сравнивается с критическим значением  , где
, где  - число объясняющих переменных.
- число объясняющих переменных.
Если 
 >
>  , то гетероскедастичность имеет место.
, то гетероскедастичность имеет место.
Рекомендации: 1) при = 30 рекомендуется выбирать с = 8, при =60
с = 16; 2) формально тест работает и без исключения наблюдений (когда n мало), но, как показывает опыт, при этом его мощность уменьшается.
Тесты Спирмена и Голдфелда-Квандта позволяют лишь обнаружить наличие или отсутствие гетероскедастичности, но не позволяют оценить количественно зависимость дисперсии от значений объясняющей переменной. С этой целью могут быть использованы тесты Уайта, Парка, Глейзера.
4. Тест Уайта
Содержательный смысл этого теста состоит в следующем. Если в модели присутствует гетероскедастичность, то очень часто это связано с тем, что дисперсии ошибок некоторым образом (возможно, довольно сложно) зависят от регрессоров, а гетероскедастичность должна как-то отражаться в остатках обычной регрессии исходной модели. Этот тест является предпочтительным для анализа множественной регрессии, когда зависимость остатков от факторов носит сложный характер.
Этот тест предполагает, что дисперсия ошибок регрессии представляет собой квадратичную функцию от значений объясняющих переменных, т.е. при наличии одного фактора
е2 = с0 +с1Х +с2Х2 , (4.5)
или при наличии m факторов
 (4.6)
(4.6)
Примечание. Для упрощения анализа, слагаемые с парными произведениями факторов, как правило, не используются.
С помощью МНК оцениваются параметры (4.5) или (4.6). С использованием распределения Стьюдента осуществляется оценка статистической значимости коэффициентов сi c целью исключения из (4.5), (4.6) незначимых слагаемых. О наличии или отсутствии гетероскедастичности судят по величине F – критерия Фишера
 , (4.7)
, (4.7)
где R2 – коэффициент детерминации.
Если >  , то гетероскедастичность присутствует и в качестве модели при вычислении дисперсии может быть использована зависимость вида (4.5) или (4.6).
, то гетероскедастичность присутствует и в качестве модели при вычислении дисперсии может быть использована зависимость вида (4.5) или (4.6).
5. Тест Парка
Здесь предполагается, что дисперсия остатков связана со значениями факторов функцией
 . (4.8)
. (4.8)
Оценим (4.8) по МНК, предварительно прологарифмировав его
 , (4.9)
, (4.9)
где  ;
;  .
.
Проверяется статистическая значимость коэффициента с1 с использованием t-статистики (Тнабл = с1/Sc1). Если коэффициент значим, то модель дисперсии может быть принята в виде (4.8). Для множественной регрессии зависимость вида (4.8) формируется для переменной Хj, которая наибольшим образом влияет на распределение  .
.
6. Тест Глейзера
Этот тест основан на проверке зависимостей остатков  от объясняющих переменных вида
от объясняющих переменных вида
 (4.10)
(4.10)
Регрессии строятся при различных значениях k и выбирается та функция, для которой коэффициент с1 наиболее значим статистически (проверяется с помощью критерия Стьюдента) или наиболее значимо уравнение (4.10) в целом (используется распределение Фишера для R2). Обычно k =…; –1; –0,5; 0,5; 1;…
Методы смягчения проблемы гетероскедастичности
Основным методом коррекции влияния гетероскедастичености является взвешенный метод наименьших квадратов (ВМНК).
Суть ВМНК: минимизируется не сумма квадратов остатков  , а взвешенная сумма квадратов
, а взвешенная сумма квадратов
 , (4.11)
, (4.11)
где  – вес i-ой ошибки.
– вес i-ой ошибки.
В случае гетеросекдастичности в качестве выбирается величина обратная дисперсии, с целью уменьшения веса измерений с большими ошибками
 . (4.12)
. (4.12)
В этом случае ВМНК можно трансформировать в МНК, если принять, что уравнение регрессии имеет вид
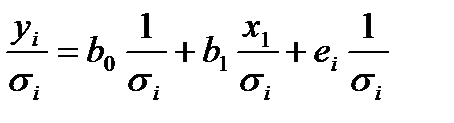 . (4.13)
. (4.13)
С помощью замены переменных (4.13) приводится к стандартному уравнению регрессии и посредством процедуры МНК вычисляются оценки b0 и b1.
Для множественной регрессии оценка коэффициентов уравнения вычисляется с помощью ВМНК по формуле
 , (4.14)
, (4.14)
где R-1 – диагональная матрица, элементами которой являются  ,
,  , Здесь приняты обозначения аналогичные рассмотренным в Главе II.
, Здесь приняты обозначения аналогичные рассмотренным в Главе II.
Для реализации алгоритма ВМНК (в случае множественной регрессии) на ЭВМ с помощью комплексных функций ЛИНЕЙН и РЕГРЕССИЯ необходимо исходное уравнение преобразовать к виду
 , (4.15)
, (4.15)
где  ,
,  ,
,  , …
, …
Эмпирическая корректировка уравнения регрессии
Так как значения дисперсий 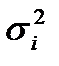 на самом деле неизвестны, то в качестве их оценок предлагается использовать наиболее предпочтительное представление
на самом деле неизвестны, то в качестве их оценок предлагается использовать наиболее предпочтительное представление 
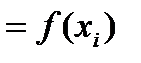 , полученное с помощью одного из вышерассмотренных тестов (Уайта, Парка, Глейзера). В этом случае аргументы уравнения (4.15) будут следующими:
, полученное с помощью одного из вышерассмотренных тестов (Уайта, Парка, Глейзера). В этом случае аргументы уравнения (4.15) будут следующими:
 ,
,  ,
,  , …,
, …,  .
.
Пример. Пусть по выборке с помощью МНК было синтезировано уравнение регрессии
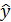
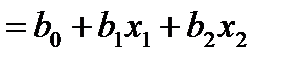 . (4.16)
. (4.16)
При этом получен ряд остатков еi . Применим к еi тест Уайта, т.е. оценим регрессию вида
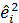
 . (4.17)
. (4.17)
С помощью обычного МНК находим сi. Для реализации ВМНК разделим все составляющие (4.16) на  и оценим его. В результате чего будут получены скорректированные оценки
и оценим его. В результате чего будут получены скорректированные оценки  и уравнение регрессии будет некоторым образом адаптировано к переменным дисперсиям ошибок измерений.
и уравнение регрессии будет некоторым образом адаптировано к переменным дисперсиям ошибок измерений.
Дата добавления: 2014-12-23; просмотров: 996; Мы поможем в написании вашей работы!; Нарушение авторских прав |